
옵저버빌리티(관측성)가 모니터링과 다른 이유, 로그·메트릭·트레이스 입문 가이드

🤖 AI Summary
모니터링은 알려진 지표를 미리 정의해두고 감시하는 활동이고, 관측성은 시스템이 만들어내는 외부 출력만으로 내부 상태를 추론할 수 있는 정도를 뜻합니다. OpenTelemetry 공식 문서는 이 영역의 데이터를 three pillars가 아니라 signals라고 부르며, 2026년 기준 Tracing·Logs·Baggage·Metrics API·OTLP가 모두 stable 단계입니다. CNCF Incubating 프로젝트로 자리잡은 OpenTelemetry는 contributors 27,737명·organizations 5,320곳 규모로 성장했고, 2026년 들어 새로운 signal인 Profiles가 Public Alpha 단계로 진입했어요. 이번 글에서는 모니터링과 관측성의 본질 차이, OpenTelemetry signals의 구조, 도입 시 자주 놓치는 비용·카디널리티 함정, 그리고 입문 팀이 어디서부터 시작하면 좋은지 단계별로 정리합니다.
블로그 목차
모니터링과 관측성, 이름은 비슷한데 무엇이 다를까요
운영팀이 자주 마주치는 상황 한 가지가 있죠. 대시보드의 CPU·메모리 그래프는 평온한데, 사용자만 응답이 느리다고 합니다. 알람은 안 울렸고, 정해둔 임계값을 넘긴 지표도 없습니다. 그런데 매출 동선에 있는 결제 페이지가 5초 넘게 멈춰 있다는 제보가 들어오죠. 이 상황이 모니터링과 관측성이 갈리는 지점입니다.
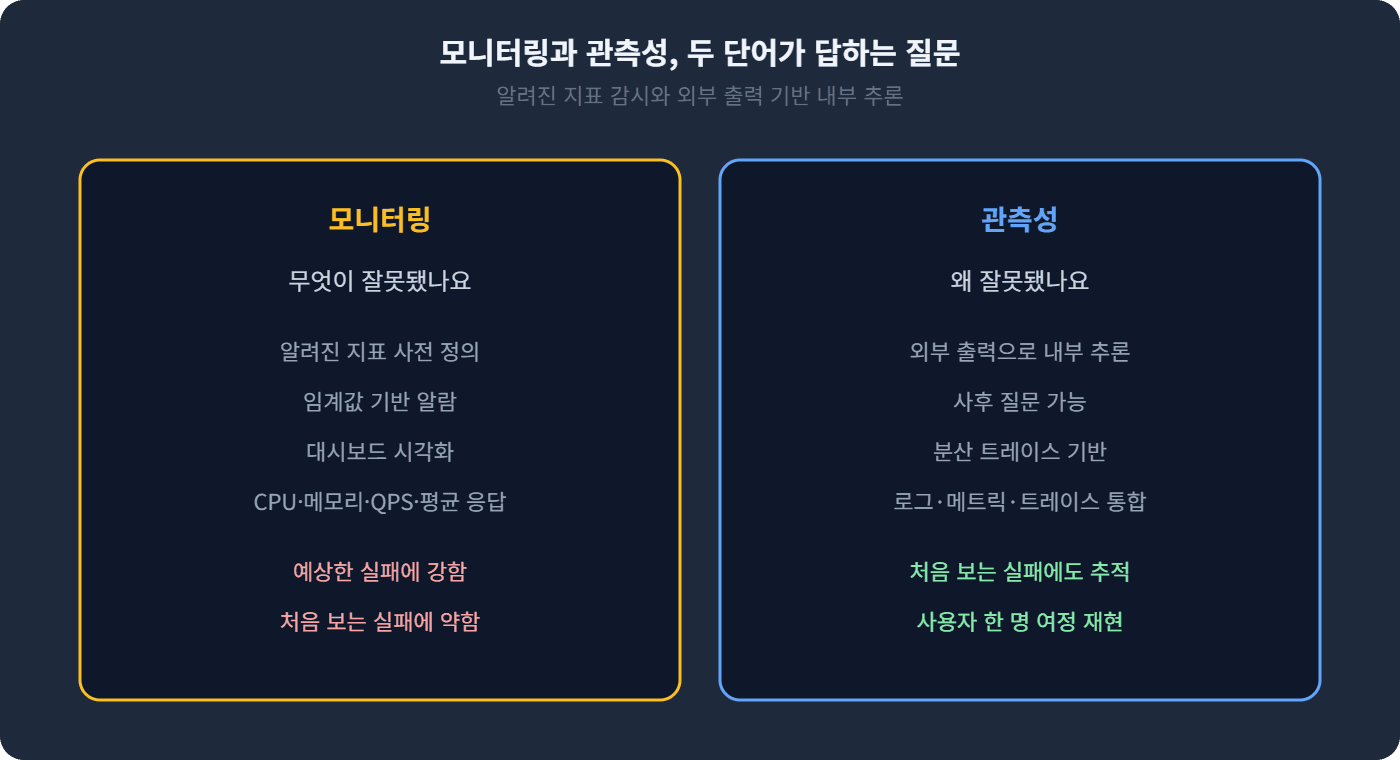
OpenTelemetry 공식 문서는 관측성을 다음 의미로 정의합니다. 시스템 외부에서 그 시스템의 내부 동작을 알지 못한 채 질문을 던질 수 있게 해주는 정도, 그게 관측성이라는 설명이에요. 모니터링은 무엇을 볼지 미리 정해두고 그 값을 감시하는 활동입니다. 알려진 실패에 강하지만, 처음 보는 실패에는 약한 구조죠.
그래서 두 단어는 같은 영역에 있지만 다른 질문에 답합니다. 모니터링은 무엇이 잘못됐나요에 답하고, 관측성은 왜 잘못됐나요에 답할 수 있게 합니다. 결제 페이지가 느려진 사건에서 모니터링은 어느 서비스의 평균 응답이 올라갔다는 사실까지 보여주지만, 관측성은 그 안에서 어떤 호출이 어떤 다운스트림을 기다리다 느려졌는지까지 따라갈 수 있게 해주죠.
OpenTelemetry는 그 데이터를 signals라고 부릅니다
관측성 도입을 검토할 때 자주 들리는 표현이 있어요. 로그·메트릭·트레이스 3축 또는 three pillars라는 말이죠. 그런데 OpenTelemetry 공식 문서는 이 데이터를 three pillars로 부르지 않습니다. signals라는 단어를 씁니다. 같은 페이지에 다음 문장이 있어요. 애플리케이션 코드는 traces, metrics, logs와 같은 signals를 내보내야 한다는 설명입니다.
이 용어 차이가 사소해 보이지만 중요한 이유가 있습니다. signals라는 표현은 추가될 여지를 열어두는 단어예요. 실제로 OpenTelemetry는 2026년 들어 새로운 signal인 Profiles를 Public Alpha 단계로 진입시켰습니다(OpenTelemetry 공식 블로그). three pillars라는 표현으로는 이 확장을 자연스럽게 받아들이기 어렵습니다. 본문에서도 이 글은 signals 표현을 따라가겠습니다.
그렇다면 현재 어떤 signal이 어디까지 안정화됐는지가 궁금해질 수 있죠. OpenTelemetry 공식 사양 상태 페이지 기준으로 정리하면 다음과 같습니다.
Signal | API / SDK | Protocol (OTLP) |
|---|---|---|
Traces | stable | stable |
Metrics | API stable, SDK mixed | stable |
Logs | Bridge API·SDK stable | stable |
Baggage | stable | — |
Profiles | — | development |
표 기준 출처: OpenTelemetry 공식 사양 상태 페이지. Profiles는 2026년 OpenTelemetry 공식 블로그에서 Public Alpha 진입이 발표됐으나, 사양 상태 페이지에는 API/SDK 항목이 별도 등재되지 않은 상태입니다.
핵심 정보를 한 문장으로 다시 정리하면 이렇습니다. Tracing·Logs·Baggage·Metrics API·OTLP는 이미 stable 단계에 도달했고, Metrics SDK 일부와 Profiles는 아직 안정화 도중이라는 점입니다. 도입을 시작하기에 충분히 무르익은 표준이라는 의미죠.
메트릭만 봐서는 놓치는 장애가 있습니다
입문 팀에게 큰 함정 한 가지가 있어요. 메트릭을 충분히 보고 있다고 느끼는 단계입니다. CPU·메모리·요청 수·평균 응답 시간을 다 보고 있고, 알람도 걸려 있죠. 그런데 사용자 화면에서는 페이지가 도중에 멈춥니다. 메트릭은 평균값과 누적값을 보여주는 데에 강하지만, 사용자 한 명의 한 요청에서 어떤 일이 일어났는지는 보여주지 못합니다.
분산 트레이스가 여기서 차이를 만듭니다. 결제 한 건이 어떤 마이크로서비스를 거쳤고, 각 서비스에서 얼마나 머물렀으며, 어떤 외부 호출이 어디서 느려졌는지를 한 줄의 trace로 따라갈 수 있어요. 메트릭이 전체 평균을 보여준다면, 트레이스는 한 사용자의 실제 여정을 보여줍니다. 그리고 로그를 trace_id 기준으로 묶으면, 그 여정에서 무슨 일이 일어났는지까지 함께 읽을 수 있죠.
이 흐름은 어떤 운영 환경에서도 동일하게 적용됩니다. 4월 27일(월) 발행 클라우드 로그 관리 글에서도 로그를 단순히 쌓는 것이 아니라 분석 가능한 형태로 구조화해야 한다고 정리했던 이유가 같은 맥락입니다. 로그·메트릭·트레이스가 따로 놀면 평균값만 잘 나오고, 사건의 인과는 끝까지 알 수 없는 상태가 됩니다.
도입 전 알아둘 비용·카디널리티 함정
관측성 도입에서 자주 무너지는 지점이 비용입니다. signals를 모으는 일은 비교적 쉽지만, 모은 데이터를 보관하고 조회하는 비용이 운영 진행과 함께 늘어나죠. 이 글에서 짚을 세 가지 함정은 다음과 같습니다.
1. 메트릭 카디널리티 폭증
메트릭 한 종류에 user_id·session_id·request_id 같은 고유 식별자 label을 붙이면 시계열 수가 곱셈으로 늘어납니다. Prometheus·OpenTelemetry 어느 쪽이든 시계열 수가 곧 비용이라 도입 초기부터 label 설계 가이드를 정해두는 게 좋아요. 사용자별 식별이 필요한 데이터는 메트릭이 아니라 로그·트레이스로 분리하면 카디널리티 문제를 완화할 수 있습니다.
2. 트레이스 전수 수집의 부담
분산 트레이스를 모든 요청에 대해 수집하면 데이터 양이 그만큼 늘어납니다. head 단계 또는 tail 단계 샘플링을 도입해 정상 트래픽은 일부만, 오류·느린 응답은 전수 수집하는 식의 정책을 쓰면 수집 비용을 조절할 수 있어요. 입문 단계에서는 낮은 샘플링 비율로 시작해 운영 데이터를 보며 점진 조정하는 방식을 선택할 수 있습니다.
3. 무제한 로그 보관
로그를 모두 장기 보관하면 스토리지 비용이 시간이 갈수록 누적됩니다. 운영 단계의 hot 보관, 분석용 warm 보관, 감사용 cold 보관 같은 계층 구조를 도입 단계부터 설계하면 비용 곡선이 안정화돼요. 로그 전체를 길게 보관하지 말고, 어떤 로그가 어떤 목적으로 얼마나 필요한지를 먼저 정의하는 것이 첫 단계입니다.
Profiles signal이 더해진 2026년
입문 단계 팀이라도 표준이 어디로 가고 있는지는 알아두면 좋습니다. 2026년 들어 눈에 띄는 변화는 Profiles signal Public Alpha 진입입니다. 기존 traces·metrics·logs·baggage signals에 더해 애플리케이션 자원 사용을 시간 흐름에 따라 보여주는 새로운 signal이 추가된 것이죠. 메트릭이 무엇이 느려졌는지 알려준다면, Profile은 그 안의 어떤 함수가 CPU·메모리를 잡고 있는지까지 좁혀줍니다(OpenTelemetry 2026년 블로그).
이 변화의 의미가 있어요. 표준이 정착되는 동시에 다룰 수 있는 signal 종류 자체가 늘어나고 있다는 점입니다. 2026년 5월 기준 CNCF 프로젝트 페이지는 OpenTelemetry가 CNCF Incubating 단계에 있으며 contributors 27,737명·organizations 5,320곳·GitHub stars 12,890개 규모로 성장했다고 안내합니다. 표준이 자리잡고 있다는 직접적인 신호입니다.
입문 팀이 시작하기 좋은 순서
전부 한 번에 도입하면 비용도 운영 부담도 커집니다. 입문 단계에서는 단계별로 한 signal씩 넓혀가는 방식이 부담이 적어요. 이 글에서는 다음 순서를 제안합니다.
1. 트래픽이 많은 서비스 한두 곳부터 메트릭 표준화
전체 서비스에 일괄 적용하기 전에 매출 동선의 한두 서비스부터 시작합니다. Prometheus 또는 OpenTelemetry Metrics SDK로 핵심 지표(QPS·에러율·지연 시간 분포)를 표준화하고, Grafana 대시보드를 한 장 만들어 운영팀이 함께 보는 합의 지점을 만드는 단계입니다.
2. 분산 트레이스 도입과 trace_id 전파
서비스 간 호출 흐름을 가시화하기 위해 OpenTelemetry SDK로 trace를 도입합니다. 핵심은 trace_id가 마이크로서비스 사이로 전파되도록 미들웨어를 설정하는 일이에요. 이 단계만 잘 마쳐도 결제 한 건이 어디서 지연이 발생했는지를 호출 단위로 식별할 수 있게 됩니다.
3. 로그를 trace_id 기준으로 묶기
이미 적재되고 있는 애플리케이션 로그에 trace_id를 함께 기록하기 시작합니다. 그러면 트레이스에서 어떤 호출이 느렸는지 본 다음, 같은 trace_id로 로그를 조회해 어떤 예외가 던져졌는지까지 한 화면에서 확인할 수 있어요.
4. 샘플링·보관 정책의 실제 수치 합의
앞서 비용 함정에서 짚었던 카디널리티·샘플링·보관 정책을 도입 단계에서 실제 수치로 합의해두는 단계입니다. 정상 트레이스 샘플링 비율, 오류 응답 수집 기준, 로그 보관 구간(hot·warm·cold) 같은 구체 수치를 한 번 합의해두면 이후 비용 곡선이 안정화됩니다. 이 합의 없이 도입하면 비용 곡선이 시간이 지날수록 올라가는 경우가 생깁니다.
5. 외부 합성 모니터링 병행
내부 관측성만으로는 사용자 체감 지연을 다 잡기 어려운 경우가 있습니다. Datadog Synthetics, Pingdom, UptimeRobot 같은 외부 합성 모니터링을 별도 회선으로 두면 우리 시스템이 멈췄을 때 그 사실을 외부에서 먼저 알 수 있어요. 클라우드 자체가 멈춘 사례는 5월 12일(화) 발행 AWS use1-az4 글에서 정리한 5월 7일 사건처럼 내부 모니터링이 같은 클라우드 위에 있다면 함께 멈출 위험이 있으니, 외부 회선의 합성 모니터링이 운영 안전망에 함께 들어가야 하는 이유입니다.
이것만 기억하세요
모니터링은 알려진 지표를 감시하는 활동이고 관측성은 외부 출력으로 내부를 추론할 수 있는 정도라는 게 두 단어의 핵심 차이입니다. OpenTelemetry 공식 문서는 데이터를 three pillars가 아니라 signals라고 부르며, 2026년 기준 Tracing·Logs·Baggage·Metrics API·OTLP가 모두 stable 단계에 도달했고 새로운 signal인 Profiles가 Public Alpha로 진입했습니다. 입문 팀은 한 번에 모든 signal을 도입하기보다 핵심 서비스 메트릭 표준화 → 분산 트레이스 도입 → 로그 trace_id 연결 → 샘플링·보관 정책 → 외부 합성 모니터링 5단계로 넓혀가는 순서가 비용·운영 부담을 줄이는 출발선입니다.
자주 묻는 질문 (FAQ)
Q. 단일 모놀리식 환경에도 관측성이 꼭 필요한가요?
단일 모놀리식 환경에서 알려진 임계값만 잘 감시하면 되는 경우에는 모니터링만으로 충분한 경우가 있습니다. 다만 마이크로서비스로 분리되거나 외부 SaaS·결제 게이트웨이를 다수 호출하는 구조에서는 평균 지표만으로는 사용자 한 명의 한 요청이 어디서 느려졌는지 파악하기 어려워집니다. 호출 경로가 두 단계 이상 늘어났다면 관측성 도입을 검토할 시점입니다.
Q. OpenTelemetry는 무엇인가요?
OpenTelemetry는 CNCF Incubating 단계 프로젝트로, 애플리케이션이 만들어내는 로그·메트릭·트레이스 같은 데이터를 표준 형식으로 수집하고 전송하기 위한 오픈소스 프레임워크입니다. OpenTelemetry 공식 문서는 이 데이터를 three pillars가 아니라 signals라고 부르며, 2026년 기준 Tracing·Logs·Baggage·Metrics API·OTLP가 모두 stable 상태입니다.
Q. 오픈소스와 상용 SaaS 중 어느 도구를 골라야 하나요?
운영 환경 규모와 기존 스택에 따라 답이 달라집니다. 클라우드 네이티브 환경에서는 OpenTelemetry SDK로 데이터를 수집한 다음 Prometheus·Grafana·Loki·Tempo 같은 오픈소스 백엔드를 직접 운영하거나, Datadog·New Relic 같은 상용 SaaS 백엔드로 보내는 방식을 선택할 수 있습니다. 처음부터 한 벤더에 락인되지 않도록 수집 단계는 표준 OpenTelemetry로 두고 백엔드만 선택하는 전략이 입문 팀에게 도움이 됩니다.
Q. 관측성 도구 비용이 폭증하는 이유는 무엇인가요?
메트릭의 카디널리티 폭증, 무제한 로그 보관, 트레이스 전수 수집이 잘 알려진 원인입니다. label 조합이 늘어나면 시계열 수가 곱셈으로 증가하고, 로그를 모두 장기 보관하면 스토리지 비용이 시간이 갈수록 누적됩니다. 샘플링 전략과 보관 정책을 도입 초기부터 함께 설계하는 것이 도움이 됩니다.
Q. Profiles signal은 무엇인가요?
Profiles는 OpenTelemetry가 2026년 들어 Public Alpha 단계로 진입시킨 새로운 signal로, 애플리케이션이 CPU·메모리·블로킹 같은 자원을 어디서 얼마나 쓰는지 시간 흐름에 따라 보여주는 데이터입니다. 기존 메트릭이 무엇이 느려졌는지를 알려준다면, Profile은 그 안의 어떤 함수가 자원을 잡고 있는지까지 좁혀줍니다.




