
클라우드 인프라, 개별 서비스는 아는데 전체 구조가 안 보인다면

실무에서 자주 마주하는 딜레마
EC2 인스턴스는 생성할 줄 압니다. RDS 설정도 했고, S3도 사용 중입니다. 그런데 장애가 발생하면 어디서부터 확인해야 할지 막막합니다 |
|---|
국내 많은 기업의 개발팀과 인프라 담당자가 겪는 공통적인 문제입니다. 클라우드 서비스별 사용법은 온라인 문서와 튜토리얼로 익힐 수 있습니다.
하지만 물리 서버부터 하이퍼바이저, 네트워크 가상화까지 이어지는 클라우드 인프라의 전체 작동 원리를 이해하는 것은 별개의 문제입니다.
특히 성능 이슈나 장애 상황에서 이런 지식 공백은 치명적입니다.
인스턴스 응답 속도가 갑자기 느려졌는데 CPU 사용률은 10%입니다라는 상황에서 근본 원인을 파악하지 못하면, 임시방편적 대응만 반복하게 됩니다.
⚡왜 전체 그림이 보이지 않는가
추상화가 만드는 블랙박스
클라우드의 핵심 가치는 추상화입니다. 물리 서버, 네트워크 장비, 스토리지 시스템 등 복잡한 인프라를 API 호출 하나로 제공합니다. 온프레미스 환경에서는 서버실에 가서 물리 서버를 보고, 케이블을 확인하고, LED 상태를 점검할 수 있었습니다. 시스템이 어떻게 구성되어 있는지 눈으로 확인 가능했죠.
클라우드는 다릅니다. 콘솔에서 버튼을 클릭하면 인스턴스가 생성되었습니다라는 메시지만 표시됩니다. 그 뒤에서 일어나는 자원 할당, 가상화, 네트워크 연결 과정은 모두 감춰져 있습니다.
파편화된 학습 자료의 한계
대부분의 클라우드 교육 자료는 특정 서비스의 사용법에 집중합니다. EC2 인스턴스 생성 방법, RDS 데이터베이스 설정 가이드, S3 버킷 권한 관리 등입니다. 각 주제별로는 상세하지만, 서비스 간 연결 관계와 하부 인프라 작동 원리는 다루지 않습니다.
Gartner의 2024년 클라우드 스킬 갭 리포트에 따르면, 기업의 68%가 클라우드 서비스 활용법은 아는데 아키텍처 설계와 문제 해결 역량이 부족하다고 응답했습니다.
⚡클라우드 인프라의 6개 계층 구조
클라우드는 물리 하드웨어부터 사용자 인터페이스까지 여러 계층으로 구성됩니다. 각 계층을 이해하면 전체 시스템이 어떻게 유기적으로 작동하는지 보입니다.
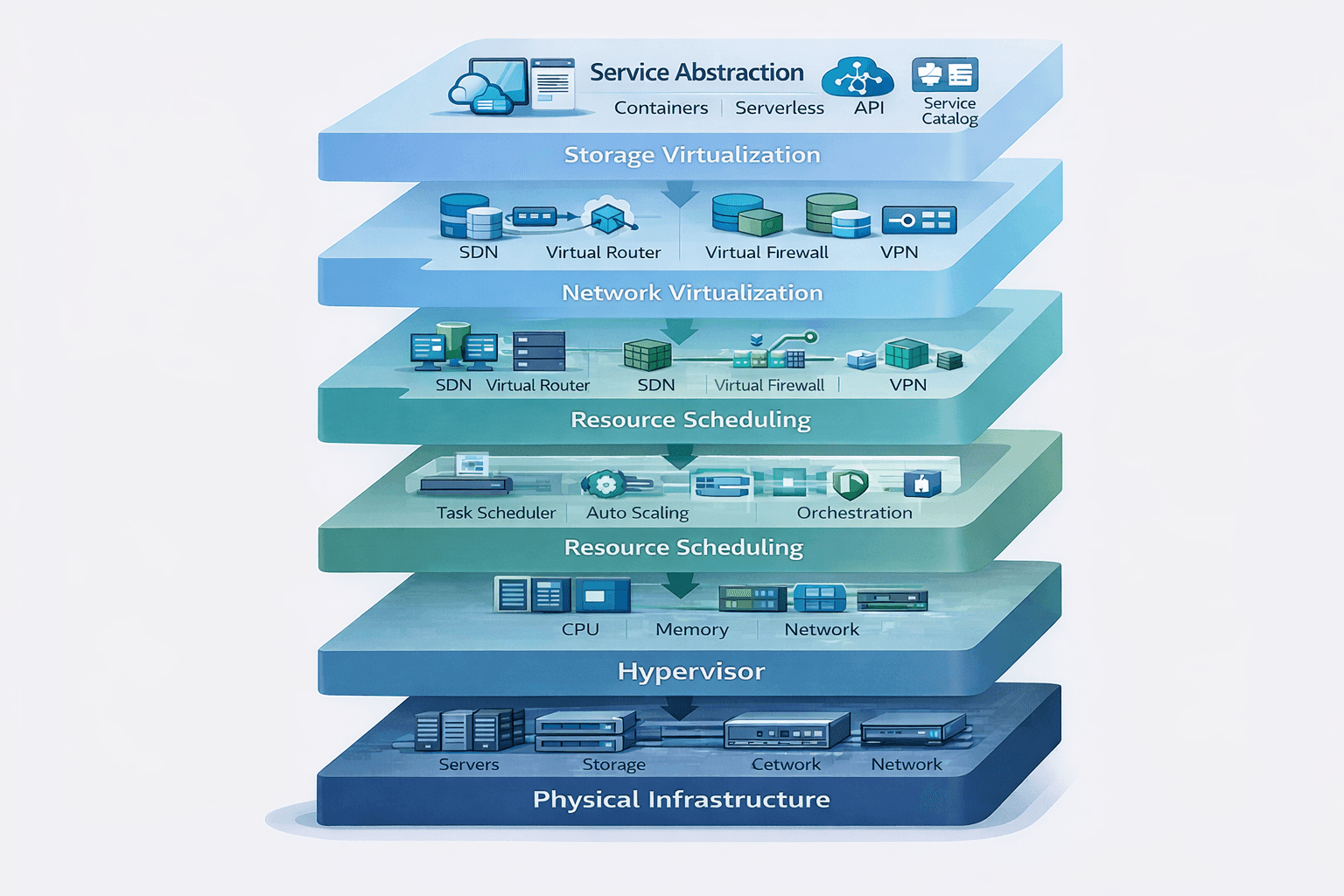
1계층: 물리 인프라
핵심: 클라우드도 결국 물리 서버 위에서 작동합니다.
AWS 서울 리전의 데이터센터에는 수십만 대의 물리 서버가 운영됩니다. 컴퓨팅 집약적 작업용은 최신 AMD EPYC 또는 Intel Xeon 프로세서를, 메모리 집약적 작업용은 512GB~1TB RAM을 탑재합니다. 이들은 여러 가용 영역(Availability Zone)에 분산 배치됩니다.
사용자가 생성하는 모든 EC2 인스턴스는 이 물리 서버 중 정확히 어느 한 대 위에서 실행됩니다. 추상적으로 클라우드 어딘가가 아니라, 특정 랙의 특정 서버에서 구동되는 것입니다.
2계층: 하이퍼바이저
핵심: 하나의 물리 서버를 여러 개의 가상 서버로 분할합니다.
AWS는 자체 개발한 Nitro Hypervisor를 사용합니다. CPU 64코어, RAM 256GB인 물리 서버를 예로 들면
가상 인스턴스 A: CPU 4코어, RAM 16GB
가상 인스턴스 B: CPU 8코어, RAM 32GB
가상 인스턴스 C: CPU 2코어, RAM 8GB
각 가상 인스턴스는 완전히 격리된 환경에서 독립적인 운영체제를 실행합니다. Nitro의 특징은 가상화 오버헤드가 5% 미만으로, 물리 서버와 거의 동등한 성능을 제공한다는 점입니다.
3계층: 자원 스케줄링
핵심: AWS가 수많은 물리 서버 중 최적의 위치를 결정합니다.
인스턴스 생성 요청 시 플레이스먼트 시스템이 고려하는 요소:
가용 자원: 요청한 스펙을 수용할 여유가 있는 호스트 검색
부하 분산: 특정 서버에 워크로드 집중 방지 (Noisy Neighbor 문제 최소화)
Placement Group: 클러스터형은 물리적으로 가깝게, 분산형은 멀리 배치
가용 영역: 지정된 AZ 또는 가장 여유 있는 AZ 자동 선택
이 계산이 수 초 내에 완료되고, 최적 서버의 하이퍼바이저에 생성 명령이 전달됩니다.
4계층: 네트워크 가상화
핵심: 물리 네트워크 카드 하나를 소프트웨어로 다중화합니다.
AWS VPC는 완전한 소프트웨어 정의 네트워크입니다. 물리 라우터, 스위치, 방화벽 없이 모든 라우팅과 패킷 필터링을 소프트웨어로 처리합니다.
각 가상 인스턴스는 가상 NIC를 할당받으며, AWS Nitro Card가 네트워크 처리를 전담합니다. CPU 부담 없이 최대 100Gbps 대역폭을 처리할 수 있는 이유입니다.
VPC의 라우팅 테이블, Security Group, Network ACL은 분산 컨트롤러가 실시간으로 적용하므로 설정 변경이 즉시 반영됩니다.
5계층: 스토리지 가상화
핵심: 디스크는 인스턴스와 분리된 별도 클러스터에서 관리됩니다.
EBS는 스토리지 전용 서버 클러스터에서 운영됩니다. 인스턴스는 네트워크를 통해 이 스토리지에 접근하지만, AWS 내부 네트워크(25~100Gbps)가 워낙 빠르기 때문에 로컬 디스크처럼 작동합니다.
[분리 구조의 장점]
인스턴스 삭제해도 데이터 유지
인스턴스 타입 변경 시에도 같은 디스크 사용
자동 복제로 하드웨어 장애에도 데이터 보호
스냅샷으로 손쉬운 백업 및 복제
io2 Block Express는 최대 256,000 IOPS, 4,000 MB/s 처리량을 지원하여 대부분의 로컬 SSD보다 빠른 성능을 제공합니다.
6계층: 서비스 추상화
핵심: 복잡한 인프라를 API 하나로 제공합니다.
사용자가 Launch Instance 버튼을 클릭하면 10~15초 안에
1) API 요청 인증 및 검증
2) 자원 확보 및 예약
3) 가상 머신 생성
4) 스토리지 할당 및 연결
5) 네트워크 구성
6) 운영체제 부팅
이 모든 과정이 자동으로 완료됩니다. 클라우드의 핵심 가치는 바로 이 추상화입니다.
⚡실제 예시: t3.medium 인스턴스 생성의 내부 프로세스
이론적 이해를 넘어, 실제로 인스턴스 하나를 생성할 때 각 계층에서 무슨 일이 일어나는지 추적해봅시다.
요청 접수 (0.1초)
콘솔에서 "Launch Instance" 클릭 → API Gateway가 IAM 권한, 서비스 쿼터, 가용 영역 가용성 검증 → EC2 Control Plane으로 라우팅
자원 확보 (0.5초)
Placement System이 서울 리전의 물리 서버 중 t3.medium(CPU 2코어, RAM 4GB) 요구사항을 충족하는 서버 검색 → 가용 영역 2a의 호스트 선택 (현재 CPU 여유 16코어, 메모리 여유 48GB) → 자원 예약
가상 머신 생성 (1~2초)
Nitro Hypervisor가 물리 CPU 2코어 격리, 메모리 4GB 할당 → 가상 머신 껍데기 완성 (아직 운영체제 없음)
스토리지 연결 (1~2초)
스토리지 클러스터에 8GB gp3 볼륨 할당 → AMI(예: Amazon Linux 2023) 이미지 복사 → 네트워크를 통해 가상 머신에 연결 (가상 머신은 로컬 디스크로 인식)
네트워크 구성 (1초)
ENI 생성 → 프라이빗 IP 할당(예: 10.0.1.50) → Security Group 규칙 적용 → 퍼블릭 IP 할당(요청 시) → 소프트웨어 라우터가 라우팅 테이블 업데이트
운영체제 부팅 (5~10초)
가상 머신 "전원" ON → EBS에서 부트로더 실행 → 리눅스 커널 로드 → systemd 서비스 시작 → cloud-init이 메타데이터에서 호스트명, SSH 키 설정
서비스 준비 (총 8~15초)
"Running" 상태 전환 → SSH 포트 대기 → 사용자 접속 가능
표면적으로는 하나의 독립적인 서버이지만, 실제로는 여러 계층의 가상화 기술이 조합된 결과물입니다.
⚡장애 대응 시나리오: 구조 이해가 필수인 순간
전체 구조 이해는 장애 상황에서 진가를 발휘합니다.

시나리오 1: 인스턴스 성능 저하
▶ 증상: EC2 응답 시간이 2~3배 증가. CPU 15%, 메모리 30%로 자원 여유 충분. 애플리케이션 로그 정상.
▶ 구조를 모르면: 코드 문제? 데이터베이스 쿼리? / 구조를 알면: 가상화 환경 특성상 같은 물리 호스트의 다른 인스턴스가 자원을 과도하게 사용하면 CPU 스케줄링 경합 발생 → Noisy Neighbor 문제 의심
▶ 해결: 인스턴스 Stop 후 Start → 다른 물리 호스트에 재배치 → 문제 해결
▶ 예방: Dedicated Host, Dedicated Instance, 또는 Placement Group으로 인스턴스 배치 제어
시나리오 2: 디스크 I/O 성능 급락
▶ 증상: EBS gp2 볼륨 사용 중 갑자기 쓰기 속도 저하. 볼륨 용량 50% 사용, 에러 로그 없음.
▶ 구조를 모르면: 디스크 고장? 용량 부족? / 구조를 알면: EBS gp2는 버스트 크레딧 시스템. 기본 성능(3 IOPS/GB) 초과 작업은 크레딧 소비 → 크레딧 소진 시 기본 성능으로 제한
▶ 확인: CloudWatch BurstBalance 메트릭 → 0%에 가까우면 크레딧 소진이 원인
▶ 해결
단기: 볼륨 크기 증가 (100GB → 200GB = 300 IOPS → 600 IOPS)
장기: gp3 전환 (크레딧 없는 일정 성능) 또는 io2 (프로비저닝 IOPS)
시나리오 3: VPC 피어링 후 통신 실패
▶ 증상: VPC 피어링 생성 완료(Active 상태)했으나 인스턴스 간 통신 불가.
▶ 구조를 모르면: 피어링 설정 오류? AWS 버그? / 구조를 알면: VPC 피어링은 물리 연결이 아닌 소프트웨어 라우팅 규칙. 피어링 연결만으로는 트래픽 자동 전달 안 됨.
▶ 체크 포인트
각 VPC 라우팅 테이블에 상대방 CIDR 경로 추가 여부
Security Group이 상대방 CIDR/SG ID 허용 여부
Network ACL 차단 여부
▶ 해결
VPC A 라우팅 테이블: 10.1.0.0/16 → pcx-xxxxx
VPC B 라우팅 테이블: 10.0.0.0/16 → pcx-xxxxx
Security Group에서 상대방 CIDR 허용
클라우드 인프라의 전체 구조를 이해하는 것은 실무에서 성능 최적화, 장애 대응, 비용 효율화를 위해 반드시 필요한 역량입니다.
6개 계층(물리 인프라 → 하이퍼바이저 → 자원 스케줄링 → 네트워크 가상화 → 스토리지 가상화 → 서비스 추상화)을 이해하면, 개별 서비스의 작동 원리를 추론할 수 있습니다. 새로운 서비스를 만나도 이것은 어느 계층에서 작동하며, 다른 서비스와 어떻게 연결되는가를 빠르게 파악할 수 있습니다.
클라우드 인프라의 전체 구조를 이해했다면 이제 실무에 적용해보세요.




