
클라우드 오토스케일링 설정 가이드 – 트래픽 급증에도 서비스 다운 없이 대응하는 법

새벽 2시, 갑자기 울린 장애 알람
한 스타트업 CTO의 전화가 울렸습니다. 서버가 응답하지 않습니다.
스피디는 지난 7년간 100개 이상의 기업에 클라우드 인프라를 구축하며 이런 상황을 수 없이 목격했습니다
이커머스 플랫폼을 운영하는 이 회사는 예상치 못한 마케팅 이벤트로 트래픽이 평소의 3배로 급증했고,
서버는 이를 감당하지 못하고 다운됐습니다.
급히 수동으로 서버를 증설했지만, 새 서버가 준비되는 동안 30분 넘게 서비스가 중단됐습니다.
매출 손실은 물론, 고객 신뢰까지 잃는 순간이었습니다.
이런 문제는 클라우드 오토스케일링으로 해결할 수 있습니다.
1️⃣ 오토스케일링이란 무엇인가?
오토스케일링(Auto Scaling)은 트래픽 변화에 따라 서버 자원을 자동으로 늘리거나 줄이는 기술입니다.
CPU 사용률, 메모리, 네트워크 트래픽 등의 지표를 실시간으로 모니터링하다가 설정한 임계값을 넘으면 자동으로 서버를 추가합니다.
수동 증설과의 가장 큰 차이는 속도와 자동화입니다.
수동으로는 서버를 추가하는 데 최소 1020분이 걸리지만, 오토스케일링은 23분 안에 새 서버를 투입할 수 있습니다.
오토스케일링이 필요한 경우
시간대별로 트래픽 편차가 큰 서비스 (예: 점심시간 배달앱)
이벤트나 프로모션으로 트래픽이 급증하는 경우
예측 불가능한 트래픽 패턴을 가진 서비스
24시간 운영팀이 없는 스타트업
2️⃣ 오토스케일링 작동 원리
오토스케일링은 크게 스케일 아웃과 스케일 업 두 가지 방식으로 작동합니다.
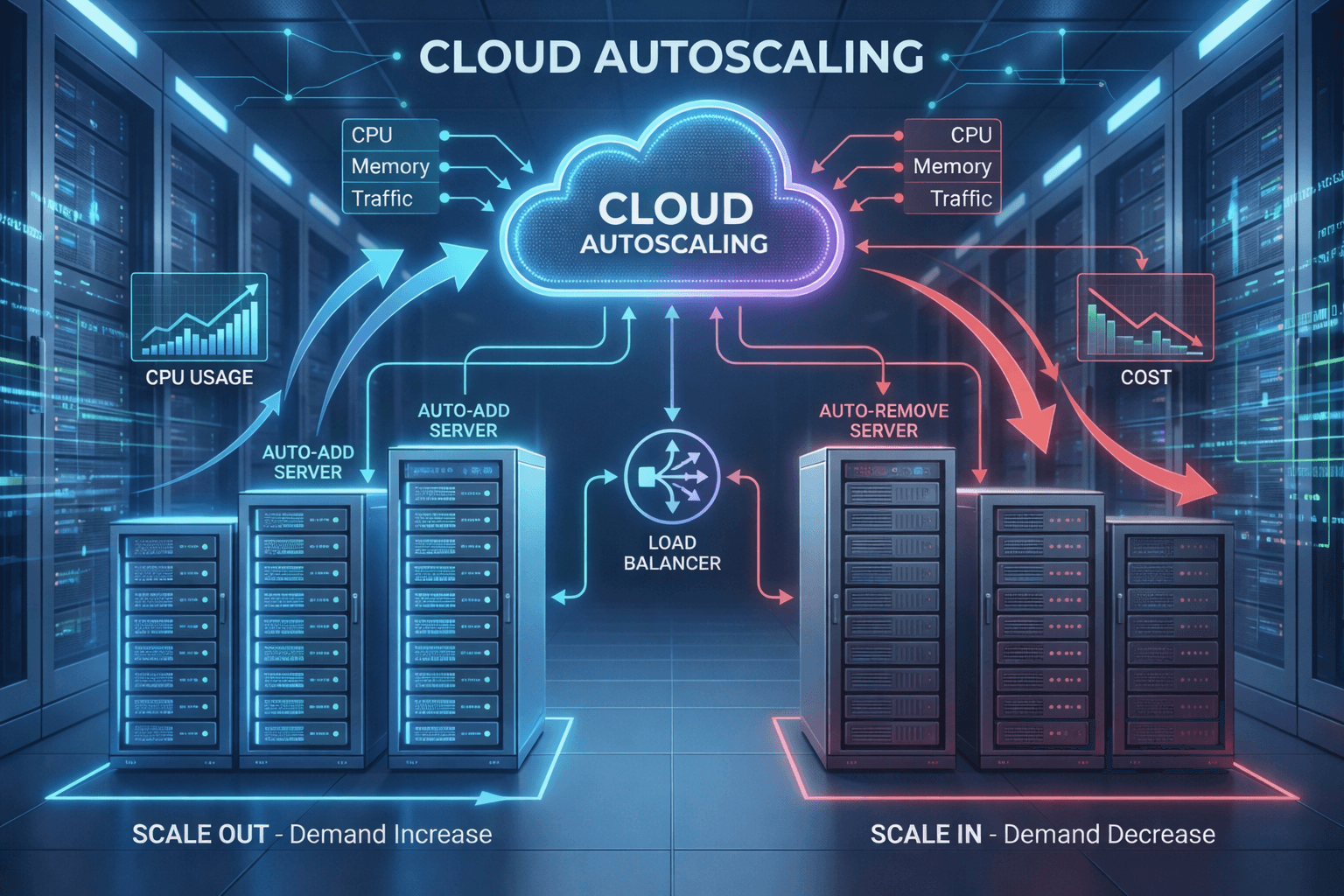
스케일 아웃(Scale Out)은 서버의 개수를 늘리는 방식입니다.
예를 들어 CPU 사용률이 70%를 넘으면 2대였던 서버를 4대로 늘립니다.
웹 애플리케이션처럼 수평 확장이 가능한 시스템에 적합합니다.
스케일 업(Scale Up)은 서버의 성능 자체를 높이는 방식입니다.
2코어 4GB 서버를 4코어 8GB로 업그레이드하는 식입니다.
데이터베이스처럼 수평 확장이 어려운 시스템에 주로 사용됩니다.
대부분의 클라우드 오토스케일링은 스케일 아웃 방식을 기본으로 합니다.
AWS의 공식 백서에 따르면,
스케일 아웃 방식은 스케일 업 대비 약 40% 높은 가용성을 제공하며, 장애 발생 시 영향 범위를 최소화할 수 있습니다.
모니터링 지표가 설정한 임계값을 넘으면 미리 준비된 이미지로 새 인스턴스를 생성하고, 로드밸런서에 자동으로 연결합니다.
3️⃣ 설정 전 반드시 확인해야 할 체크리스트
오토스케일링을 설정하기 전에 애플리케이션 구조부터 점검해야 합니다.
준비 없이 설정하면 오히려 장애가 발생할 수 있습니다.
애플리케이션이 Stateless 구조인가? | 세션 정보나 사용자 데이터를 서버 로컬에 저장하면 안 됩니다. 서버가 늘어나거나 줄어들 때 데이터가 유실될 수 있기 때문입니다. |
|---|---|
헬스체크 엔드포인트가 있는가? | 로드밸런서가 서버의 상태를 확인할 수 있는 URL이 필요합니다. |
AMI 또는 이미지가 준비되어 있는가? | 새 서버가 생성될 때 사용할 이미지가 필요합니다. |
로드밸런서가 설정되어 있는가? | 오토스케일링은 로드밸런서와 함께 작동합니다. |
4️⃣ 단계별 오토스케일링 설정 가이드
주요 클라우드별 설정 흐름은 비슷합니다. 여기서는 공통적인 설정 단계를 중심으로 설명하겠습니다.
Step 1: 시작 템플릿(Launch Template) 생성
새 인스턴스가 어떤 사양으로 생성될지 정의합니다.
인스턴스 타입 (예: t3.medium)
AMI ID (애플리케이션이 포함된 이미지)
보안 그룹
키 페어
사용자 데이터(User Data) - 시작 시 실행할 스크립트
Step 2: Auto Scaling 그룹 생성
시작 템플릿을 기반으로 Auto Scaling 그룹을 만듭니다.
최소 인스턴스 수: 2개 (가용성 확보)
최대 인스턴스 수: 10개 (비용 상한선)
원하는 용량: 2개 (평상시 유지할 수)
서브넷: 여러 가용 영역에 분산 배치
Step 3: 스케일링 정책 설정
언제, 얼마나 늘리고 줄일지 정책을 정합니다.
대상 추적 스케일링(Target Tracking)이 가장 쉽고 효과적입니다.
평균 CPU 사용률을 60%로 유지라고 설정하면 자동으로 인스턴스를 조절합니다.
CPU, 네트워크, 커스텀 메트릭 등을 기준으로 설정 가능합니다.
단계별 스케일링(Step Scaling)은 더 세밀한 제어가 가능합니다.
CPU 70% 이상: 인스턴스 2개 추가
CPU 85% 이상: 인스턴스 4개 추가
Step 4: 쿨다운 시간 설정
스케일링 후 다음 스케일링까지 대기하는 시간입니다.
너무 짧으면 불필요하게 인스턴스가 추가될 수 있습니다. 보통 300초(5분)로 설정합니다.
Step 5: 헬스체크 연동
로드밸런서의 헬스체크와 Auto Scaling 그룹의 헬스체크를 모두 활성화하세요.
비정상 인스턴스는 자동으로 종료되고 새 인스턴스가 투입됩니다.
5️⃣ 실전에서 놓치기 쉬운 설정 실수 3가지

쿨다운 시간을 설정하지 않음
쿨다운 없이 설정하면 트래픽이 조금만 올라도 계속 인스턴스가 추가됩니다.
한 회사는 30분 만에 서버가 100대까지 늘어나 예상치 못한 비용 폭탄을 맞았습니다.
쿨다운 시간을 최소 300초는 설정하세요.CPU 임계값을 너무 높게 설정
비용을 아끼려고 CPU 90%에서 스케일링을 시작하도록 설정하는 경우가 있습니다.
하지만 이미 서버가 과부하 상태일 때 스케일링이 시작되면 늦습니다.60~70% 정도가 적정 임계값입니다.
헬스체크 실패로 인한 무한 재시작
헬스체크 URL이 제대로 응답하지 않으면 인스턴스가 계속 종료되고 재생성됩니다.
한 팀은 데이터베이스 연결을 헬스체크에 포함했는데, DB 장애 시 모든 인스턴스가 재시작을 반복했습니다.
헬스체크는 가볍게 유지하고, 애플리케이션 기본 동작만 확인하세요.
6️⃣ 비용 효율적인 오토스케일링 정책 설정 팁
스케줄 기반 스케일링 활용
트래픽 패턴을 예측할 수 있다면 스케줄 기반 스케일링을 사용하세요.
예를 들어 점심시간(11:0014:00)에 미리 서버를 늘리고, 새벽(01:0006:00)에는 최소한만 유지할 수 있습니다.예측 스케일링(Predictive Scaling) 고려
AWS, Azure는 머신러닝을 활용한 예측 스케일링을 제공합니다.
과거 트래픽 패턴을 학습해 미리 서버를 준비합니다. 이벤트가 많은 서비스라면 효과적입니다.적정 인스턴스 타입 선택
처음부터 큰 인스턴스를 쓰는 것보다 작은 인스턴스를 여러 개 쓰는 게 비용 효율적입니다.
t3.medium 1대보다 t3.small 2대가 더 유연하게 확장됩니다.
단, 너무 작으면 오버헤드가 커지니 적정 균형을 찾으세요.
💡 더 많은 비용 절감 방법이 궁금하다면
[클라우드 서버 비용 절감하는 방법] 글에서 환율 활용, 예약 인스턴스 등 다양한 전략을 확인해보세요.
Spot 인스턴스 혼합 사용
가격이 저렴한 Spot 인스턴스를 일부 포함하면 최대 70~90%까지 비용을 절감할 수 있습니다.
단, Spot은 중단될 수 있으므로 온디맨드와 혼합해서 사용하는 것이 안전합니다.
7️⃣ 운영 안정성을 위한 다음 단계
오토스케일링을 설정했다면 이제 지속적인 모니터링이 필요합니다.
확인해야 할 지표
평균 인스턴스 수 추이
스케일링 발생 빈도
CPU/메모리 사용률 패턴
비용 변화 추이
CloudWatch, Azure Monitor, NHN Cloud Monitoring 같은 도구를 활용하면 실시간으로 상태를 확인할 수 있습니다.
알람을 설정해두면 비정상적인 스케일링이 발생했을 때 즉시 대응할 수 있습니다.
만약 클라우드 운영에 전담 인력을 투입하기 어렵다면 MSP(Managed Service Provider) 활용을 고려해보세요. |
|---|
💡 MSP가 클라우드 전환에 꼭 필요한 이유가 궁금하다면?**
👉 클라우드 전환, 직접 하면 실패하고 MSP를 쓰면 성공하는 이유 글에서 실제 성공/실패 사례를 확인해보세요.
최근 스피디가 NHN Cloud 기반으로 구축한 A사(게임 업체)의 경우, 오토스케일링 도입 후 다음과 같은 성과를 얻었습니다:
트래픽 5배 급증 시에도 서비스 안정성 100% 유지
비용은 수동 운영 대비 32% 절감 (과다 프로비저닝 방지)
평균 응답 시간 18% 개선
오토스케일링은 설정으로 끝나는 것이 아니라 지속적인 튜닝이 필요합니다.
처음에는 보수적으로 설정하고, 실제 트래픽 패턴을 보면서 점진적으로 조정하세요.
그리고 정기적으로 비용과 성능을 검토하며 최적의 균형점을 찾아가는 것이 중요합니다.

자주 묻는 질문 (FAQ)
Q. 오토스케일링 설정 비용은 얼마나 드나요?
A. 클라우드 서비스마다 다르지만, 오토스케일링 자체는 무료입니다. 추가된 서버 인스턴스 사용량만 과금됩니다.
Q. 중소기업도 오토스케일링이 필요한가요?
A. 예. 트래픽 변동이 있다면 규모와 관계없이 필요합니다. 오히려 전담 인력이 부족한 중소기업일수록 더 중요합니다.
Q. 설정 후 얼마나 지나야 효과를 볼 수 있나요?
A. 설정 즉시 적용되지만, 최적화까지는 1~2주 정도 모니터링하며 튜닝하는 것이 좋습니다.




