
서버 이중화만으로 충분할까? 가용성 99.9%와 99.99%의 현실적 차이

🤖 AI Summary
서버 이중화는 고가용성의 출발점이지만, 그것만으로 SLA 99.99%를 달성할 수는 없습니다. 가용성 99.9%와 99.99% 사이에는 연간 다운타임 기준으로 약 8시간의 차이가 존재하며, 이 격차를 줄이려면 네트워크, 스토리지, DB, DNS까지 전체 아키텍처를 이중화해야 합니다. 이 글에서는 SLA 가용성 수치의 실제 의미를 데이터로 분석하고, 서버 이중화의 한계를 넘는 고가용성 설계 전략을 정리합니다.
블로그 목차
서버 이중화를 했는데도 장애가 발생한다면
서버 이중화를 구축했으니 안심하고 계신가요? 많은 기업이 서버를 두 대로 늘리는 것만으로 고가용성을 확보했다고 생각하곤 하죠. 하지만 현실은 다릅니다. 2025년 10월, AWS US-EAST-1 리전에서 대규모 장애가 발생했을 때 서버 자체는 이중화되어 있었지만 DNS 레코드 오류 하나로 15시간 넘게 서비스가 중단됐습니다.
같은 해 10월 Microsoft Azure에서도 네트워킹 구성 변경 하나가 약 50시간의 장애를 일으켰습니다. 서버 이중화가 되어 있어도 네트워크, DNS, 스토리지 같은 다른 구성 요소에 단일 장애점(Single Point of Failure)이 남아 있으면, 전체 서비스가 멈출 수 있습니다.
이 글에서는 SLA 가용성 수치가 실제로 의미하는 바를 숫자로 확인하고, 서버 이중화를 넘어 진짜 고가용성을 확보하기 위해 어떤 설계가 필요한지 살펴보겠습니다.
SLA 가용성 수치, 숫자 하나의 차이가 만드는 격차
SLA(Service Level Agreement)에서 가용성은 보통 퍼센트로 표현됩니다. 99.9%와 99.99%는 숫자상으로는 0.09%밖에 차이 나지 않는데요. 실제 허용 다운타임으로 환산하면 이야기가 완전히 달라집니다.
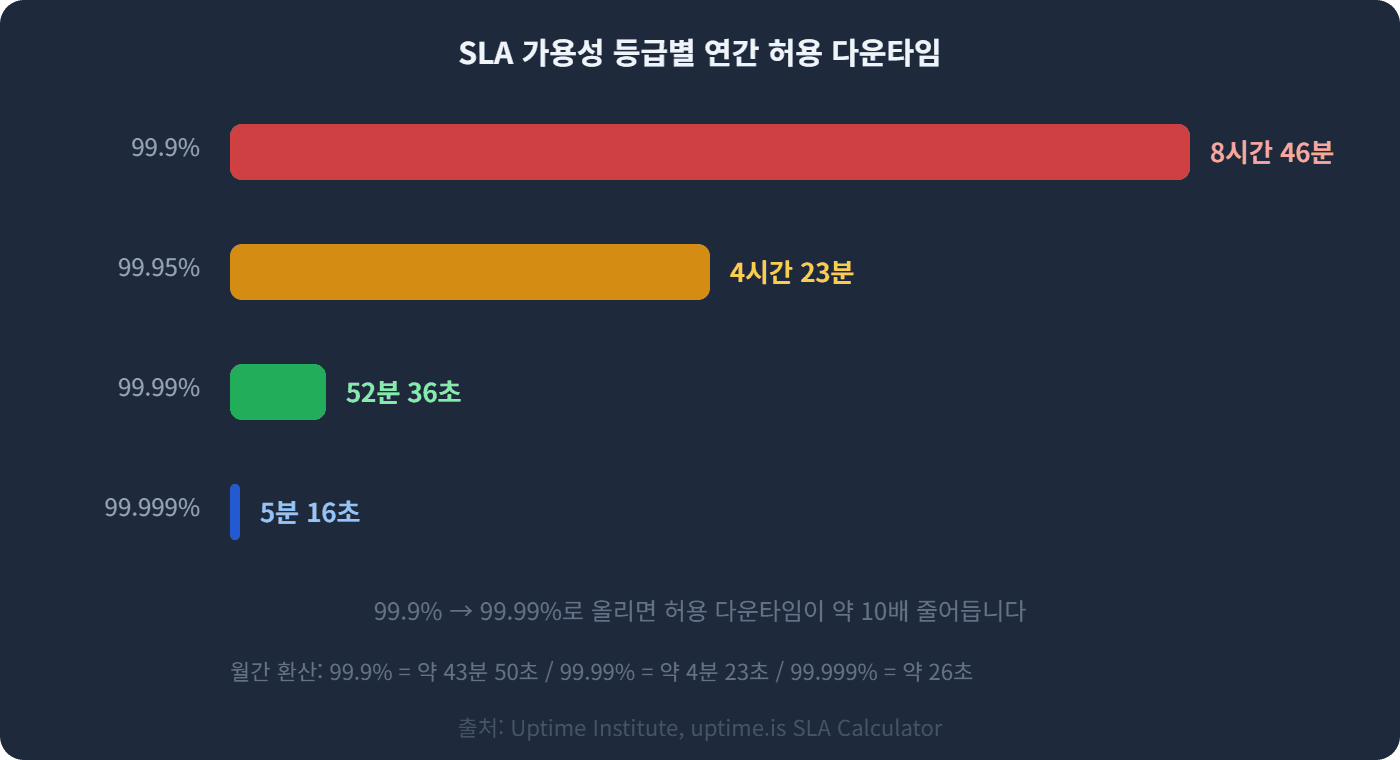
정리하면 이렇습니다.
SLA 가용성 | 연간 다운타임 | 월간 다운타임 | 일간 다운타임 |
|---|---|---|---|
99.9% (쓰리 나인) | 8시간 46분 | 43분 50초 | 1분 26초 |
99.95% | 4시간 23분 | 21분 55초 | 43초 |
99.99% (포 나인) | 52분 36초 | 4분 23초 | 8.6초 |
99.999% (파이브 나인) | 5분 16초 | 26초 | 0.86초 |
99.9%는 비즈니스 애플리케이션에서 가장 흔한 SLA 가용성 목표입니다. 하지만 이것은 연간 약 8시간 46분의 다운타임을 허용한다는 뜻이에요. 결제 시스템, 인증 서버, 핵심 인프라처럼 1분의 중단도 큰 손실로 이어지는 서비스라면, 99.99% 이상이 필요하겠죠.
가용성 99.9%에서 99.99%로 한 자릿수를 올리는 데 필요한 투자는, 99%에서 99.9%로 올리는 것보다 몇 배 이상 커집니다. 그만큼 아키텍처 전반에 걸친 정교한 설계가 요구됩니다.
서버 이중화의 기본: Active-Active vs Active-Standby
서버 이중화는 크게 두 가지 방식으로 나뉩니다. 각 방식의 특성을 이해해야 올바른 설계를 할 수 있습니다.
Active-Active 방식
HA 클러스터로 연결된 모든 서버가 동시에 활성 상태로 동작합니다. 로드 밸런서가 트래픽을 분산 처리하며, 한쪽 서버에 장애가 발생하면 나머지 서버가 즉시 트래픽을 흡수합니다.
장점: 별도의 페일오버(Failover) 전환 시간이 거의 없고, 평상시에도 양쪽 서버 자원을 모두 활용해 처리량이 높습니다.
단점: 한 서버 장애 시 나머지 서버에 부하가 집중됩니다. 용량 설계를 각 서버 60% 수준으로 운영하고 있었다면, 한 대 장애 시 120%를 감당해야 하므로 연쇄 장애가 발생할 수 있습니다.
Active-Standby 방식
1차 서버가 모든 서비스를 처리하고, 2차 서버는 대기 상태로 있다가 장애 시 자동 전환됩니다. Active-Passive라고도 부릅니다.
장점: 네트워크 구성이 단순하고, 장애 시 처리 용량이 줄어들지 않습니다.
단점: 페일오버 전환 시간(수 초~수 분) 동안 서비스 중단이 발생합니다. 대기 서버의 자원이 평상시에는 유휴 상태입니다.
두 방식 모두 서버 이중화의 기본 형태입니다. 하지만 여기서 중요한 질문이 하나 있습니다. 서버를 이중화했다고 해서, 정말로 서비스 전체의 가용성이 올라갈까요?
서버 이중화만으로는 99.99%에 도달할 수 없는 이유
서비스가 사용자에게 도달하기까지의 경로를 생각해 보세요. 사용자의 요청은 DNS 조회 → 네트워크 → 로드 밸런서 → 서버 → 애플리케이션 → 데이터베이스 → 스토리지를 거칩니다. 이 중 하나라도 단일 장애점이 있으면, 서버를 아무리 이중화해도 전체 SLA 가용성은 올라가지 않습니다.
전체 아키텍처에서 놓치기 쉬운 단일 장애점
DNS: 2025년 AWS 장애의 근본 원인이 DNS 레코드 오류였습니다. DNS가 단일 구성이면 서버가 살아있어도 사용자가 접속할 수 없습니다.
네트워크: Azure 장애는 네트워킹 구성 변경 하나로 50시간 장애를 일으켰습니다. 스위치, 라우터, 방화벽 모두 이중화 대상입니다.
로드 밸런서: 로드 밸런서가 단일 구성이면, 서버가 여러 대여도 트래픽을 분배할 수 없습니다.
데이터베이스: DB 이중화 없이 서버만 이중화하면, DB 장애 시 모든 서버가 동시에 기능을 잃습니다.
스토리지: 공유 스토리지의 컨트롤러, 디스크, 경로(Path)까지 이중화해야 데이터 접근이 끊기지 않습니다.
전원/냉각: 물리적 인프라도 예외가 아닙니다. 데이터센터 Tier III 이상부터 전원 경로가 이중화됩니다.
가용성은 체인과 같아서, 가장 약한 고리가 전체 가용성을 결정합니다. 서버만 이중화하고 나머지 구성 요소에 단일 장애점이 남아 있다면, SLA 99.99%는 달성할 수 없습니다.

가용성 등급별 필요 구성 비교: 어디까지 이중화해야 할까
SLA 가용성 목표에 따라 이중화해야 하는 범위가 달라집니다. 아래 표는 각 가용성 등급에서 권장되는 구성을 정리한 것입니다.
구성 요소 | 99.9% (Three Nine) | 99.99% (Four Nine) | 99.999% (Five Nine) |
|---|---|---|---|
서버 | Active-Standby (N+1) | Active-Active (N+1 이상) | Active-Active (2N) |
네트워크 | 단일 경로 + 백업 회선 | 이중 경로 (듀얼 스위치) | 이중 경로 + 멀티 ISP |
로드 밸런서 | 단일 + 수동 전환 | HA 쌍(Active-Standby) | Active-Active HA 쌍 |
데이터베이스 | Primary + 수동 복제 | 동기 복제 + 자동 페일오버 | 멀티 마스터 + 지역 분산 |
스토리지 | RAID + 정기 백업 | 이중 컨트롤러 + 이중 경로 | 지역 간 미러링 (2N) |
DNS | 단일 DNS 서비스 | 멀티 DNS (2개 이상 프로바이더) | Anycast DNS + 멀티 프로바이더 |
데이터센터 | 단일 센터 (Tier II 이상) | 단일 센터 (Tier III 이상) | 이중 센터 (Tier IV) + DR |
모니터링 | 기본 모니터링 | 실시간 모니터링 + 자동 알림 | AIOps + 예측적 장애 감지 |
연간 투자 규모 | 기본 인프라 비용의 1.3~1.5배 | 기본의 2~3배 | 기본의 5~10배 이상 |
99.99% 이상을 목표로 한다면, 서버 이중화는 전체 퍼즐의 한 조각에 불과합니다. DNS, 네트워크, DB, 스토리지까지 모든 계층의 이중화가 필요합니다.
실제 장애 사례로 보는 서버 이중화의 한계
이론만으로는 와닿지 않을 수 있습니다. 최근 발생한 대형 장애 사례를 통해 서버 이중화만으로는 부족한 이유를 확인해 보겠습니다.
사례 1: AWS US-EAST-1 DNS 장애 (2025년 10월)
서버는 정상이었습니다. 하지만 DNS 레코드의 자동 업데이트 과정에서 빈 레코드가 입력되면서, 사용자가 서비스에 접속할 수 없었습니다. Netflix, Snapchat 등 수많은 서비스가 15시간 이상 중단됐고, 1,700만 건 이상의 장애 신고가 접수됐습니다.
교훈: DNS는 가장 간과되기 쉬운 단일 장애점입니다. 멀티 DNS 프로바이더 구성이 필수입니다.
사례 2: Azure 네트워킹 구성 변경 장애 (2025년 10월)
Azure의 PubSub 서비스에서 인덱싱 데이터가 손실되면서, 네트워킹 제어 평면이 개별 호스트의 에이전트에 구성을 전달하지 못했습니다. 미국 동부 2 리전에서 시작된 문제가 약 50시간 동안 지속됐으며, 연결 문제, 시간 초과, 리소스 할당 실패가 동시에 발생했습니다.
교훈: 서버가 이중화되어 있어도, 네트워크 제어 평면의 단일 변경이 전체 서비스를 마비시킬 수 있습니다.
사례 3: CrowdStrike 업데이트 장애 (2024년 7월)
보안 에이전트 업데이트 하나가 전 세계 약 850만 대의 Windows 시스템을 동시에 다운시켰습니다. 항공, 의료, 금융 등 핵심 산업이 마비됐고, 미국 Fortune 500 기업들의 피해액만 약 54억 달러로 추산됩니다.
교훈: 소프트웨어 배포 과정도 단일 장애점이 될 수 있습니다. 카나리 배포, 롤링 업데이트 같은 배포 전략이 가용성의 일부입니다.
데이터가 보여주듯, 서버 하드웨어 자체의 장애는 전체 서비스 중단 원인의 약 25%에 불과합니다. 나머지 75%는 네트워크, DNS, 소프트웨어, DB 등 서버 외부의 요인입니다. 서버 이중화만으로는 전체 장애의 4분의 1밖에 대비하지 못하는 셈이죠.
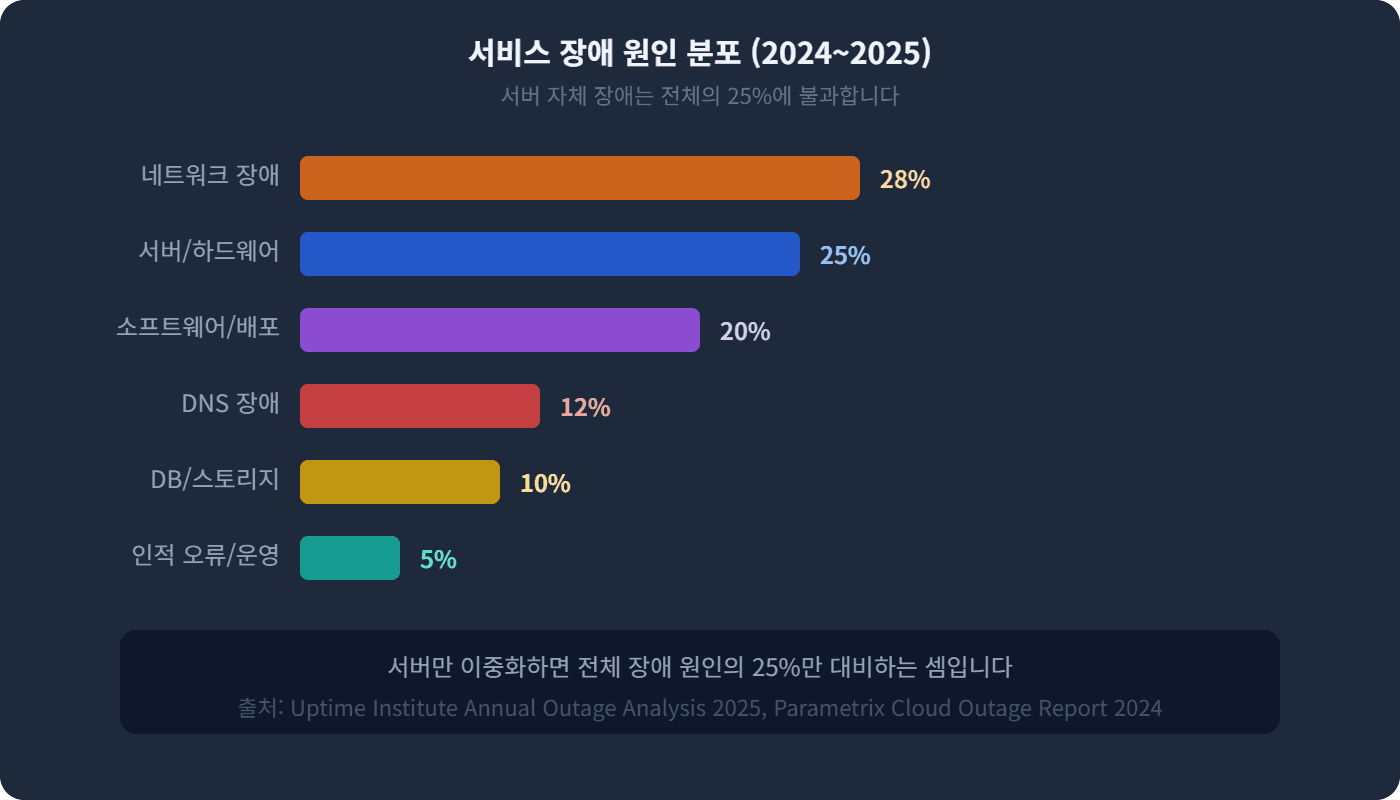
기업 규모와 서비스 특성별 권장 가용성 수준
모든 서비스가 99.999%의 SLA 가용성을 필요로 하지는 않습니다. 과도한 가용성 설계는 비용 낭비가 될 수 있고, 반대로 가용성이 부족하면 비즈니스 손실로 이어집니다. 중요한 것은 서비스 특성에 맞는 적정 수준을 찾는 것입니다.
서비스 유형 | 권장 SLA | 주요 구성 | 예시 |
|---|---|---|---|
사내 업무 시스템 | 99.9% | 서버 이중화 + 정기 백업 | 그룹웨어, ERP, 인트라넷 |
고객 대면 웹 서비스 | 99.95% | 서버 + LB + DB 이중화 | 기업 홈페이지, 고객 포털 |
전자상거래/SaaS | 99.99% | 전 계층 이중화 + 멀티 AZ | 쇼핑몰, B2B SaaS, API |
결제/인증/의료 | 99.99~99.999% | 멀티 리전 + DR + Anycast | PG사, 은행, 의료 시스템 |
기업 규모별로 보면, 중소기업은 핵심 서비스에 99.9~99.95%를, 중견기업은 99.95~99.99%를, 대기업이나 금융/의료 분야는 99.99% 이상을 목표로 설계하는 것이 일반적입니다. 비용 대비 효과를 고려한 현실적인 판단이 필요합니다.
MSP가 고가용성 설계에 기여하는 방법
고가용성 아키텍처를 자체적으로 설계하고 운영하려면 상당한 전문 인력과 경험이 필요합니다. 서버 이중화 구성뿐 아니라 네트워크, DNS, DB, 스토리지까지 전 계층을 아우르는 설계 역량과, 24/7 모니터링 및 장애 대응 체계를 갖춰야 하죠.
이런 이유로 많은 기업들이 MSP(Managed Service Provider)를 활용합니다. MSP는 다음과 같은 방식으로 고가용성 확보에 기여합니다.
아키텍처 진단 및 설계: 현재 인프라의 단일 장애점을 진단하고, 서비스 특성에 맞는 가용성 목표와 이중화 범위를 설계합니다.
멀티 클라우드/하이브리드 구성: 단일 클라우드에 의존하지 않도록 워크로드를 분산 배치하고, 클라우드 간 장애 격리를 설계합니다.
24/7 모니터링 및 즉시 대응: 장애 징후를 실시간으로 감지하고, 자동 페일오버와 수동 대응을 병행합니다.
정기적인 DR 테스트: 2024년 조사에 따르면, 실제로 DR 프로세스를 정기적으로 테스트하는 기업은 45%에 불과합니다. MSP가 이 테스트를 주기적으로 수행하고 결과를 리포트합니다.
비용 최적화: 과도한 이중화 없이 적정 수준의 가용성을 확보할 수 있도록 비용과 가용성 사이의 균형점을 찾아줍니다.
스피디는 클라우드 매니지드 서비스 전문 MSP로서, 인프라 진단부터 고가용성 설계, 구축, 운영까지 전 과정을 지원합니다. 서버 이중화를 넘어 전체 아키텍처 관점에서 가용성을 높이고 싶다면, 전문가의 진단부터 시작해 보세요.
서버 이중화를 넘어 가용성을 높이는 실무 체크리스트
지금 운영 중인 인프라의 SLA 가용성을 한 단계 끌어올리고 싶다면, 아래 체크리스트를 확인해 보세요.
단일 장애점 식별: 서비스 경로의 모든 구성 요소(DNS, 네트워크, LB, 서버, DB, 스토리지)를 점검하고, 단일 구성인 영역을 파악하세요.
가용성 목표 설정: 서비스 특성과 비즈니스 영향도를 기준으로 현실적인 SLA 목표를 정하세요. 모든 서비스가 99.99%일 필요는 없습니다.
이중화 우선순위 결정: 장애 빈도와 영향도가 큰 구성 요소부터 이중화하세요. 네트워크와 DNS가 서버보다 우선일 수 있습니다.
자동 페일오버 구성: 수동 전환은 RTO(복구 목표 시간)를 늘립니다. 가능한 모든 구간에 자동 페일오버를 적용하세요.
모니터링과 알림 체계: 장애를 감지하지 못하면 이중화가 있어도 소용없습니다. 실시간 모니터링과 즉시 알림을 구축하세요.
정기적인 장애 테스트: 페일오버가 실제로 작동하는지 주기적으로 테스트하세요. 테스트하지 않은 이중화는 신뢰할 수 없습니다.
용량 계획 검토: Active-Active 구성이라면, 한 대 장애 시 나머지 서버가 전체 부하를 감당할 수 있는지 확인하세요.
자주 묻는 질문(FAQ)
Q. 서버 이중화만 하면 SLA 99.9%는 달성할 수 있나요?
서버 이중화만으로 99.9%를 보장할 수는 없습니다. 서버 이중화는 서버 장애에 대한 대비일 뿐, 네트워크, DNS, DB 등 다른 구성 요소의 장애는 별도로 대비해야 합니다. 다만 기본적인 서버 이중화와 정기 백업, 모니터링을 갖추면 99.9%에 근접하는 것은 가능합니다.
Q. Active-Active와 Active-Standby 중 어떤 것이 더 좋은가요?
서비스 특성에 따라 다릅니다. 페일오버 시간을 최소화해야 하고 평상시 처리량도 중요하다면 Active-Active가 유리합니다. 구성을 단순하게 유지하면서 안정적인 전환이 필요하다면 Active-Standby가 적합합니다. 비용과 운영 복잡도까지 고려해서 선택하세요.
Q. 99.99%와 99.999%의 비용 차이는 얼마나 되나요?
일반적으로 99.99%를 달성하려면 기본 인프라 비용의 2~3배, 99.999%는 5~10배 이상이 필요합니다. 99.999%는 멀티 리전, 멀티 클라우드, 지역 분산 DR까지 포함하므로 비용이 기하급수적으로 증가합니다. 서비스의 비즈니스 영향도를 기준으로 적정 수준을 결정하는 것이 중요합니다.
Q. 클라우드를 사용하면 자동으로 고가용성이 보장되나요?
클라우드 자체가 고가용성을 보장하지는 않습니다. AWS, Azure, GCP 모두 리전이나 가용 영역(AZ) 단위의 장애가 발생한 사례가 있습니다. 클라우드에서도 멀티 AZ 배포, 로드 밸런싱, DB 복제 등을 직접 설계해야 원하는 가용성 수준에 도달할 수 있습니다.
Q. 이중화 테스트는 얼마나 자주 해야 하나요?
최소 분기 1회, 가능하다면 월 1회를 권장합니다. 인프라 변경이 있을 때마다 추가 테스트도 필요합니다. 2024년 조사에 따르면 정기적으로 DR 테스트를 수행하는 기업은 45%에 불과하며, 나머지 55%는 실제 장애 시 이중화가 제대로 작동하는지 검증되지 않은 상태입니다.
이것만 기억하세요
서버 이중화는 고가용성의 시작이지 완성이 아닙니다. SLA 99.99% 이상을 달성하려면, DNS부터 네트워크, 로드 밸런서, DB, 스토리지까지 서비스 경로 전체를 이중화하고, 정기적으로 테스트해야 합니다.




