
퍼블릭 클라우드 대형 장애 사례 분석! 기업 피해 규모와 실무 대응 가이드

🤖 AI Summary
2024~2026년 사이 AWS, Azure, GCP 등 주요 퍼블릭 클라우드에서 대형 장애가 반복적으로 발생했으며, 기업당 시간당 평균 30만 달러 이상의 손실이 보고되고 있습니다. 클라우드 장애는 예고 없이 찾아오기 때문에 사전 대비 전략이 핵심입니다. 이 글에서는 실제 클라우드 장애 사례를 데이터로 분석하고, 감지부터 복구까지 4단계 대응 프로세스와 멀티클라우드·DR 설계 전략을 실무 관점에서 정리합니다.
블로그 목차
클라우드 장애, 남의 일이 아닙니다
2025년 6월, Azure Active Directory 인증 장애로 전 세계 Microsoft 365 사용자가 4시간 넘게 로그인하지 못하는 사태가 발생했습니다. 같은 해 9월에는 AWS ap-northeast-1 리전에서 네트워크 장애가 일어나 국내 수십 개 서비스가 동시 마비됐습니다. 클라우드 장애는 더 이상 뉴스 속 먼 이야기가 아닙니다.
Uptime Institute 2025 보고서에 따르면, 대형 클라우드 장애의 60% 이상이 네트워크 또는 인증 시스템 오류에서 시작됩니다. 문제는 하나의 퍼블릭 클라우드에 전적으로 의존하는 기업이 이런 장애 앞에서 속수무책이라는 점입니다.
이 글에서는 최근 2년간 발생한 주요 클라우드 장애 사례를 분석하고, 기업이 실제로 겪는 피해 규모를 숫자로 확인한 뒤, 장애 발생 시 즉시 활용할 수 있는 실무 대응 프로세스를 제시합니다.
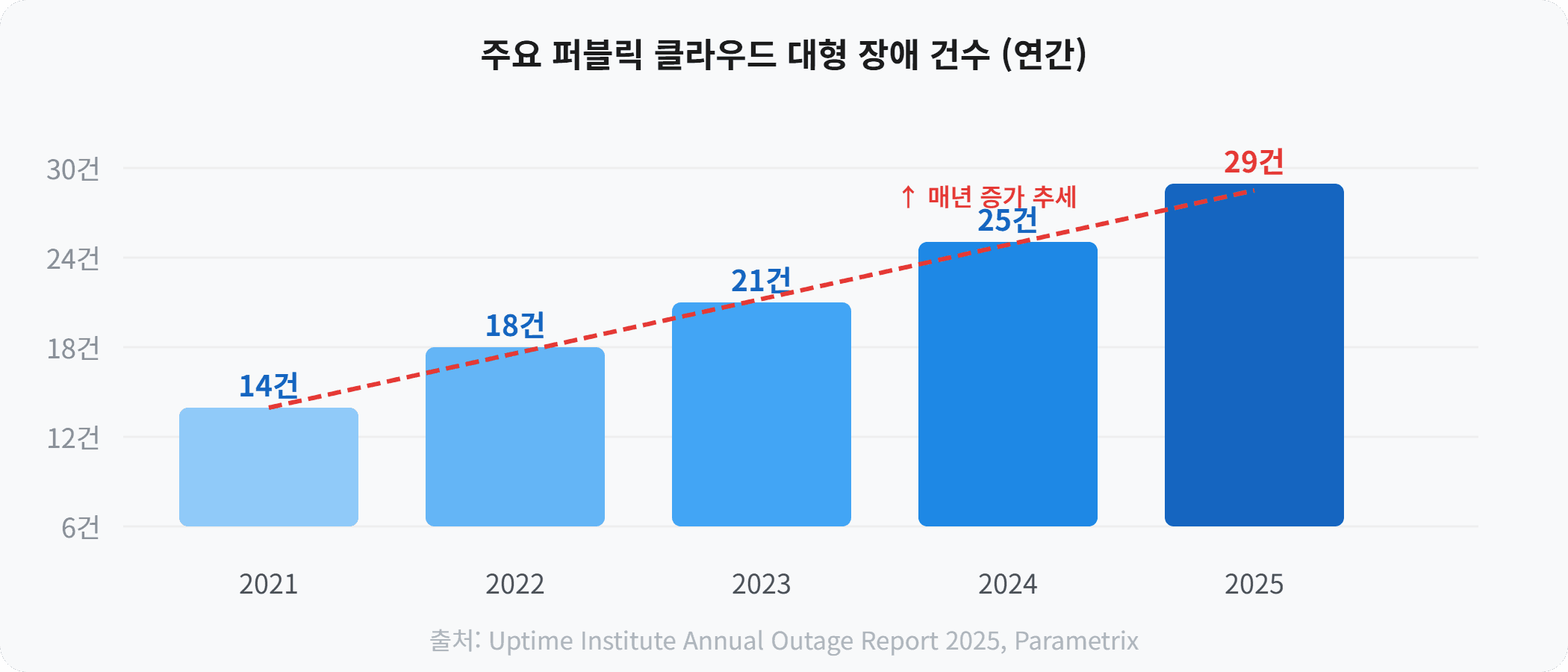
클라우드 장애, 기업에 얼마나 큰 피해를 주나요?
클라우드 장애가 발생하면 단순히 서비스가 멈추는 것으로 끝나지 않습니다. 매출 손실, 고객 이탈, 브랜드 신뢰도 하락, 그리고 복구에 투입되는 인력 비용까지 — 피해는 눈덩이처럼 불어납니다.
피해 항목 | 평균 규모 | 비고 |
|---|---|---|
시간당 매출 손실 | $300,000+ | Fortune 1000 기업 기준 (ITIC 2025) |
평균 복구 시간(MTTR) | 2~8시간 | 장애 유형에 따라 편차 큼 |
고객 이탈률 증가 | 15~25% | 4시간 이상 장애 시 (PwC 조사) |
연간 다운타임 비용 | $12.9M | 대기업 평균 (Splunk 2024) |
SLA 위반 보상 비용 | 월 요금의 10~100% | CSP별 SLA 크레딧 정책 상이 |
Parametrix 분석에 따르면, 2024년 7월 CrowdStrike 업데이트로 촉발된 전 세계적 클라우드 장애 한 건의 경제적 손실이 약 54억 달러에 달했습니다. 이 사례 하나만으로도 클라우드 장애 대비가 선택이 아닌 필수라는 사실이 명확해집니다.
특히 국내 기업은 해외 CSP(Cloud Service Provider)의 장애 상황을 영어로 된 상태 페이지에서 실시간 확인해야 하고, 기술 지원 티켓도 영어로 작성해야 하는 이중고를 겪습니다. 클라우드 장애 앞에서 언어 장벽까지 더해지면 대응 시간은 더 길어질 수밖에 없습니다.
2024~2025 주요 클라우드 장애 사례 분석
실제로 어떤 클라우드 장애가 발생했고, 어떤 영향을 미쳤는지 주요 사례를 정리했습니다.
사례 1: CrowdStrike-Azure 연쇄 장애 (2024년 7월)
보안 솔루션 CrowdStrike의 결함 있는 업데이트가 Windows 시스템에 블루스크린을 일으키면서, Azure 기반 서비스를 포함한 전 세계 850만 대 이상의 디바이스가 영향을 받았습니다. 항공사, 은행, 병원 등 핵심 인프라가 동시에 마비됐으며, 복구에 최대 수일이 소요되었습니다.
사례 2: AWS ap-southeast-2 리전 장애 (2024년 12월)
시드니 리전의 전력 공급 시스템 결함으로 EC2, RDS, EBS 등 핵심 서비스가 약 6시간 동안 중단되었습니다. 단일 가용 영역(AZ)에 워크로드를 집중한 기업은 전면 서비스 중단을 겪었고, 멀티 AZ 구성을 해둔 기업은 빠르게 복구할 수 있었습니다.
사례 3: Azure Active Directory 인증 장애 (2025년 6월)
Azure AD의 토큰 발급 시스템 오류로 Microsoft 365, Teams, Azure Portal 등이 4시간 넘게 접속 불가 상태가 되었습니다. 전 세계 수백만 명의 업무가 중단되었으며, 인증 시스템이라는 단일 장애점(SPOF)의 위험성을 여실히 보여준 사례입니다.
사례 4: GCP 네트워크 장애 (2025년 9월)
Google Cloud의 글로벌 네트워크 라우팅 설정 오류로 us-central1, europe-west1 등 여러 리전에서 동시 장애가 발생했습니다. Cloud Run, GKE, Cloud SQL 등 네트워크 의존도가 높은 서비스가 약 3시간 동안 불안정했으며, 멀티리전 구성이 아닌 서비스는 전면 중단되었습니다.
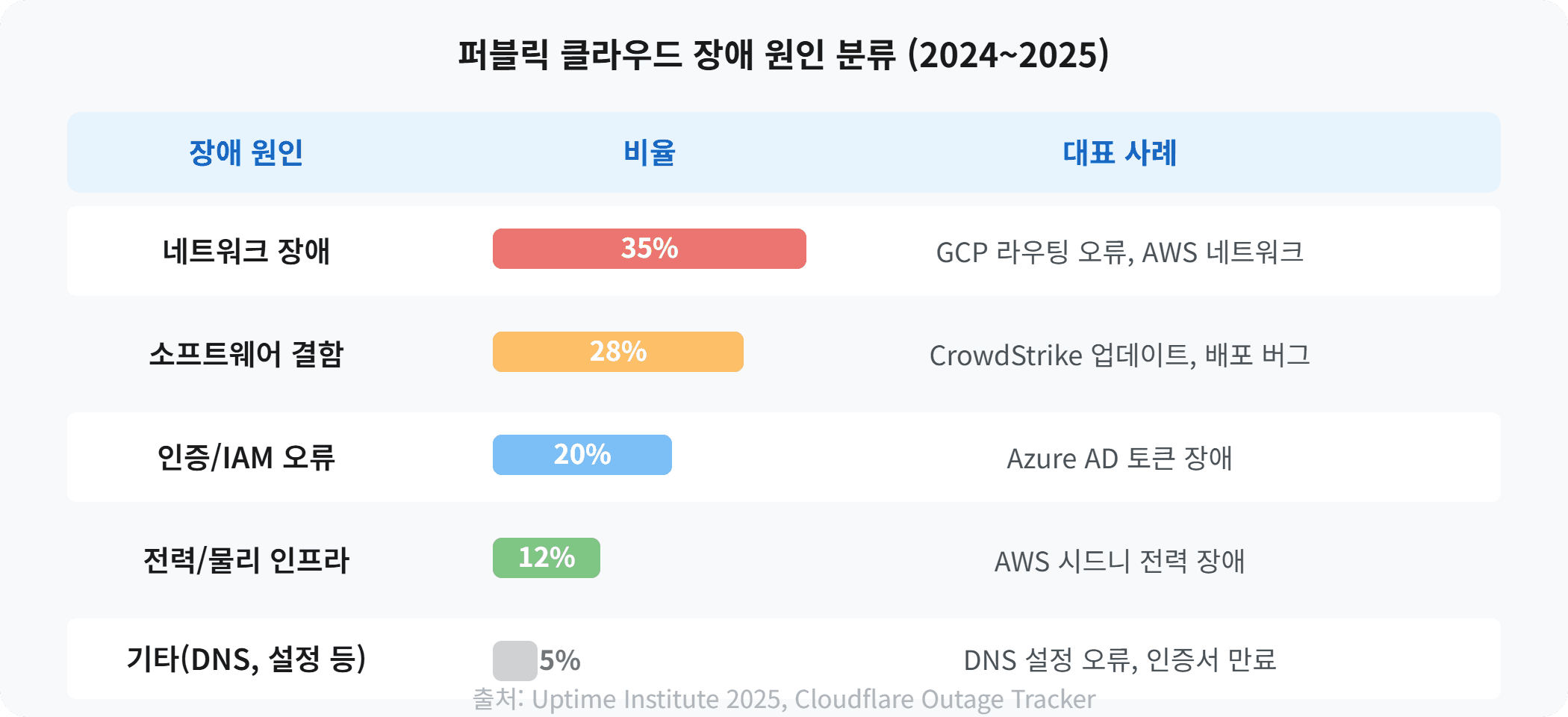
클라우드 장애 대응, 4단계 실무 프로세스
클라우드 장애는 발생 자체를 막을 수 없습니다. 중요한 것은 얼마나 빨리 감지하고, 얼마나 체계적으로 대응하느냐입니다. 아래 4단계 프로세스를 사전에 수립하고 정기적으로 훈련해두면, 장애 발생 시 복구 시간을 절반 이하로 줄일 수 있습니다.
1단계: 감지(Detection) — 장애를 가장 먼저 아는 조직이 이깁니다
CSP의 상태 페이지만 믿고 있으면 안 됩니다. 실제 사례를 보면, CSP 공식 상태 페이지 업데이트보다 자체 모니터링 알림이 평균 15~30분 빠릅니다.
헬스체크 모니터링: 핵심 엔드포인트에 대한 외부 헬스체크를 30초 간격으로 설정하세요
다중 경로 알림: Slack, SMS, PagerDuty 등 최소 2개 채널로 알림을 동시 발송하세요
CSP 상태 구독: AWS Health Dashboard, Azure Service Health, GCP Service Health를 이메일/웹훅으로 구독하세요
서드파티 모니터링: Datadog, New Relic 등으로 CSP 독립적인 외부 모니터링을 운영하세요
2단계: 에스컬레이션(Escalation) — 30분 안에 의사결정 라인 가동
장애 감지 후 가장 흔한 실패 패턴은 담당자 혼자 해결하려고 시간을 소비하는 것입니다. 사전에 에스컬레이션 매트릭스를 정의해두세요.
L1 (0~15분): 모니터링 담당자가 장애를 확인하고 초기 영향 범위를 파악합니다
L2 (15~30분): 인프라/DevOps 팀이 투입되어 원인 분석과 1차 대응을 시작합니다
L3 (30분~): CTO/VP 레벨이 비즈니스 영향을 판단하고, 고객 커뮤니케이션 여부를 결정합니다
CSP 티켓: Severity 1(긴급) 티켓을 즉시 발행하세요. Enterprise Support 등급이면 15분 내 응답을 받을 수 있습니다
3단계: 복구(Recovery) — 페일오버와 우회 경로 확보
복구 단계에서 핵심은 CSP의 장애 해결을 기다리는 것이 아니라, 자체적으로 서비스를 살리는 것입니다.
DNS 페일오버: Route 53, Cloudflare DNS의 자동 페일오버로 트래픽을 정상 리전/CSP로 전환하세요
DR 사이트 활성화: 사전에 구축한 재해복구(DR) 환경을 가동하세요. RTO(복구 목표 시간)에 맞춰 데이터 정합성을 확인하세요
캐시 서빙: CDN 캐시 또는 스태틱 페이지로 최소한의 서비스를 유지하세요
고객 안내: 상태 페이지를 업데이트하고, 장애 현황과 예상 복구 시간을 투명하게 공유하세요
4단계: 포스트모템(Post-mortem) — 같은 장애를 두 번 겪지 않기 위해
장애가 복구되면 끝이 아닙니다. 클라우드 장애 후 포스트모템 없이 넘어가는 기업은 같은 유형의 장애에 반복적으로 당합니다.
장애 타임라인을 분 단위로 기록합니다 (언제 감지했는지, 언제 에스컬레이션했는지, 언제 복구됐는지)
근본 원인(Root Cause)과 기여 요인(Contributing Factor)을 구분하여 분석합니다
개선 액션 아이템을 도출하고 담당자와 기한을 지정합니다
포스트모템 문서를 팀 전체에 공유하고, 분기별로 장애 대응 훈련에 반영합니다
클라우드 장애에 대비하는 3가지 핵심 전략
전략 1: 멀티클라우드 — 한 바구니에 모든 달걀을 담지 마세요
단일 CSP에 모든 워크로드를 올려두면, 해당 CSP에 장애가 발생했을 때 대안이 없습니다. 핵심 서비스를 최소 2개 이상의 CSP에 분산 배치하는 멀티클라우드 전략이 필요합니다.
프론트엔드는 AWS, 백엔드는 NHN Cloud처럼 역할별로 CSP를 분리하세요
DNS 레벨에서 가중치 기반 라우팅을 설정하면 장애 시 자동 전환이 가능합니다
컨테이너 기반 아키텍처(Kubernetes)를 채택하면 CSP 간 워크로드 이동이 용이합니다
전략 2: DR(재해복구) 설계 — RPO와 RTO를 숫자로 정의하세요
DR 전략 없이 운영하는 기업이 클라우드 장애 앞에서 할 수 있는 일은 CSP의 복구를 기다리는 것뿐입니다.
RPO(복구 시점 목표): 최대 허용 데이터 손실 시간을 정의하세요 (예: RPO 1시간 = 최대 1시간 분량 데이터 손실 허용)
RTO(복구 시간 목표): 서비스 복구까지 허용 가능한 최대 시간을 정의하세요 (예: RTO 30분)
정기 DR 훈련: 분기 1회 이상 페일오버 테스트를 실시하세요. 훈련하지 않은 DR 계획은 실전에서 실패합니다
전략 3: SLA 관리 — 크레딧을 받는 것보다 장애를 안 겪는 게 낫습니다
CSP의 SLA(서비스 수준 계약)는 장애 후 보상을 약속하지만, 그 보상이 실제 비즈니스 손실을 메워주지는 않습니다.
CSP별 SLA 수치를 비교하세요 (AWS EC2: 99.99%, Azure VM: 99.95%, GCP Compute: 99.99%)
SLA 크레딧 청구 절차를 사전에 파악해두세요 — 장애 후 30일 이내 청구해야 하는 경우가 대부분입니다
SLA에 포함되지 않는 장애 유형(계획된 유지보수, 사용자 설정 오류 등)을 확인하세요
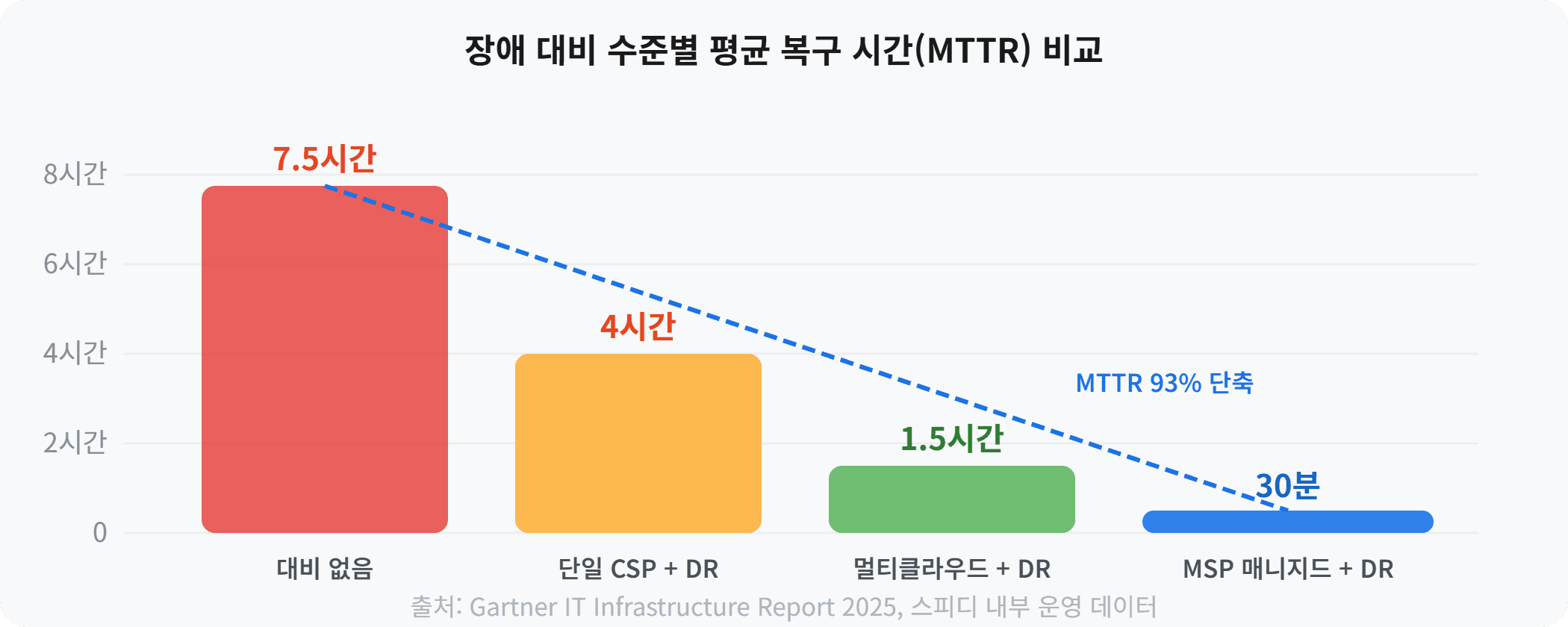
MSP를 통한 클라우드 장애 대응, 왜 다른가요?
자체적으로 24/7 모니터링 체계를 구축하고, 멀티클라우드 전문 인력을 확보하는 것은 대부분의 기업에게 현실적으로 어려운 일입니다. 이때 MSP(Managed Service Provider)의 역할이 중요해집니다.
24/7/365 모니터링: 새벽 3시에 발생한 장애도 즉시 감지하고 대응합니다. 자체 모니터링 인력을 운영하지 않아도 됩니다
멀티클라우드 전문성: AWS, Azure, GCP, NHN Cloud 등 각 CSP의 장애 패턴과 대응 방법을 숙지하고 있어 빠른 원인 분석이 가능합니다
즉시 에스컬레이션: CSP 기술 지원 채널과의 직접 소통 경로를 보유하고 있어, 영어 티켓 작성부터 후속 대응까지 원스톱으로 처리합니다
사전 DR 설계: 클라우드 장애 시나리오별 DR 계획을 수립하고 정기적으로 훈련합니다
스피디는 NHN Cloud 공식 MSP 파트너로서, 24/7/365 모니터링과 장애 즉시 대응 체계를 운영하고 있습니다. 클라우드 인프라 설계 단계부터 멀티클라우드 아키텍처와 DR 전략을 반영하여, 장애 발생 시에도 비즈니스 연속성을 보장합니다.
클라우드 장애 대비 시 흔히 하는 실수 3가지
실수 1: CSP의 SLA를 DR 전략으로 착각하기
AWS가 99.99% 가용성을 보장한다고 해서 장애가 안 생기는 것이 아닙니다. 99.99%는 연간 약 52분의 다운타임을 허용한다는 의미입니다. 그 52분이 블랙프라이데이 피크 시간에 발생하면 매출 손실은 연간 SLA 크레딧의 수십 배가 될 수 있습니다.
실수 2: DR 환경을 만들어놓고 테스트하지 않기
Gartner 조사에 따르면, DR 계획을 보유한 기업의 42%가 실제 DR 테스트를 1년 이상 하지 않았습니다. 테스트하지 않은 DR은 장애 발생 시 정상 작동한다는 보장이 없습니다. 최소 분기 1회, 전체 페일오버 시뮬레이션을 실행하세요.
실수 3: 장애 대응을 인프라팀에만 맡기기
클라우드 장애의 영향은 기술팀을 넘어 고객 서비스, 마케팅, 경영진까지 미칩니다. 고객 안내 메시지는 누가 보내는지, SNS 대응은 어떻게 하는지, 파트너사 통보는 누가 하는지 — 조직 전체의 역할을 사전에 정의해두세요.
자주 묻는 질문(FAQ)
Q. 퍼블릭 클라우드 장애가 발생하면 CSP에서 자동으로 보상해주나요?
자동 보상이 아닙니다. 대부분의 CSP는 고객이 직접 SLA 크레딧을 청구해야 하며, 장애 발생 후 30일 이내에 요청해야 합니다. 보상 범위도 해당 서비스의 월 사용료 일부에 한정되어, 실제 비즈니스 손실에 비하면 매우 적은 금액입니다.
Q. 멀티클라우드를 도입하면 비용이 많이 증가하나요?
초기 아키텍처 설계와 연동 비용이 발생하지만, 장애로 인한 매출 손실과 비교하면 투자 대비 효과가 큽니다. 모든 워크로드를 이중화할 필요는 없고, 핵심 서비스 위주로 멀티클라우드를 적용하면 비용을 합리적으로 관리할 수 있습니다.
Q. 클라우드 장애 대비와 DR 구축, 자체적으로 할 수 있나요?
가능하지만, 24/7 모니터링 인력 확보, 멀티클라우드 운영 전문성, 정기 DR 훈련 등을 자체적으로 갖추기 어려운 중소·중견기업은 MSP를 활용하는 것이 현실적인 대안입니다.
Q. NHN Cloud도 대형 장애가 발생한 적이 있나요?
모든 클라우드는 장애 가능성이 있습니다. 다만 NHN Cloud는 국내 데이터센터 기반으로 운영되어 해외 CSP 대비 국내 고객 대응 속도가 빠르고, 한국어 기술 지원이 즉시 가능하다는 점이 강점입니다.
Q. 스피디의 클라우드 장애 대응 서비스는 어떤 것이 있나요?
스피디는 24/7/365 모니터링, 멀티클라우드 아키텍처 설계, DR 구축 및 정기 훈련, 장애 발생 시 즉시 대응과 CSP 커뮤니케이션 대행까지 클라우드 장애 대응 전 과정을 매니지드 서비스로 제공합니다.
이것만 기억하세요
퍼블릭 클라우드 장애는 발생 여부가 아니라 발생 시점의 문제입니다. AWS, Azure, GCP 어떤 CSP도 100% 무장애를 보장하지 않습니다. 기업이 할 일은 단 하나 — 감지 → 에스컬레이션 → 복구 → 포스트모템, 이 4단계 대응 프로세스를 사전에 수립하고, 멀티클라우드와 DR 전략으로 단일 장애점을 제거하는 것입니다. 혼자 준비하기 어렵다면, MSP와 함께하세요.




