
Redis 서버가 계속 죽는다 — OOM Kill 무한 루프의 원인과 해결

🤖 AI Summary
캐시 용도의 Redis 서버가 수 분 간격으로 OOM Kill과 재시작을 반복하는 장애를 해결한 사례입니다. 근본 원인은 maxmemory 미설정, noeviction 기본 정책, bgsave의 fork() 메모리 부담이 합쳐진 것이었습니다. 이 글에서는 증상 확인부터 원인 분석, RDB 로딩의 함정, 실제 조치 과정, 그리고 Redis 운영에서 흔히 놓치는 설정들까지 단계별로 정리합니다.
블로그 목차
캐시 용도의 Redis 서버가 수 분 간격으로 OOM Kill과 재시작을 반복하는 장애를 해결한 사례입니다. 근본 원인은 maxmemory 미설정, noeviction 기본 정책, bgsave의 fork() 메모리 부담이 합쳐진 것이었습니다. 이 글에서는 증상 확인부터 원인 분석, RDB 로딩의 함정, 실제 조치 과정, 그리고 Redis 운영에서 흔히 놓치는 설정들까지 단계별로 정리합니다.
"Redis가 계속 죽어요." 고객사에서 긴급 연락이 왔습니다. 캐시 용도로 사용하던 Redis 서버가 수 분 간격으로 죽고, 자동으로 다시 살아나고, 또 죽기를 반복한다는 것이었습니다. 서비스에 직접적인 영향은 아직 없었지만, 캐시 히트율이 급감하면서 DB 부하가 눈에 띄게 올라가고 있었습니다. 서버에 접속해서 확인해 보니, 이건 단순한 메모리 부족 문제가 아니었습니다. 설정 하나의 부재가 연쇄적으로 문제를 일으켜, OOM Kill 무한 루프라는 최악의 상황을 만들어낸 케이스였습니다. |
|---|
증상 확인 — 서버에 접속하자마자 보인 것들
서버에 SSH로 접속한 뒤, 가장 먼저 Redis 상태를 확인했습니다.
redis-cli로 접속 시도
$ redis-cli PING
LOADING Redis is loading the dataset in memory
PONG이 아닌 LOADING 메시지가 돌아왔습니다. Redis가 RDB 파일을 메모리에 로딩하는 중이라는 뜻입니다. 몇 초 후 다시 시도하면 이번에는 아예 연결이 거부됩니다.
$ redis-cli PING
Could not connect to Redis at 127.0.0.1:6379: Connection refused
Connection refused는 Redis 프로세스 자체가 죽었다는 의미입니다. 참고로 Connection timed out은 프로세스는 살아 있지만 응답을 못 하는 상태(예: 블로킹 명령 실행 중)를 나타내므로, 둘을 구분하는 것이 진단의 첫 번째 포인트입니다.
dmesg로 OOM Kill 로그 확인
$ dmesg -T | grep -i "oom\|kill"
[Wed Mar 25 14:23:01 2026] Out of memory: Killed process 18234 (redis-server) total-vm:15823456kB, anon-rss:7845632kB
[Wed Mar 25 14:28:15 2026] Out of memory: Killed process 18567 (redis-server) total-vm:15912344kB, anon-rss:7901248kB
[Wed Mar 25 14:33:42 2026] Out of memory: Killed process 18891 (redis-server) total-vm:16001024kB, anon-rss:7956480kB
커널의 OOM Killer가 약 5분 간격으로 Redis 프로세스를 강제 종료하고 있었습니다. anon-rss 값이 약 7.5~7.6GB로, 서버 전체 메모리 8GB의 거의 전부를 Redis가 사용하고 있었습니다.
systemd의 무한 재시작 루프
$ systemctl status redis
● redis-server.service - Advanced key-value store
Active: activating (auto-restart) (Result: signal) since ...
Process: 18891 ExecStart=/usr/bin/redis-server /etc/redis/redis.conf (code=killed, signal=KILL)
Redis의 systemd 유닛 파일에 Restart=always가 설정되어 있었습니다. 이 설정 자체는 정상적이지만, OOM Kill 상황에서는 오히려 독이 됩니다. Redis가 죽으면 자동으로 재시작하고, 재시작하면 RDB 파일을 로딩하면서 다시 메모리를 가득 채우고, 또 OOM Kill을 당하는 무한 루프가 만들어지는 것입니다.
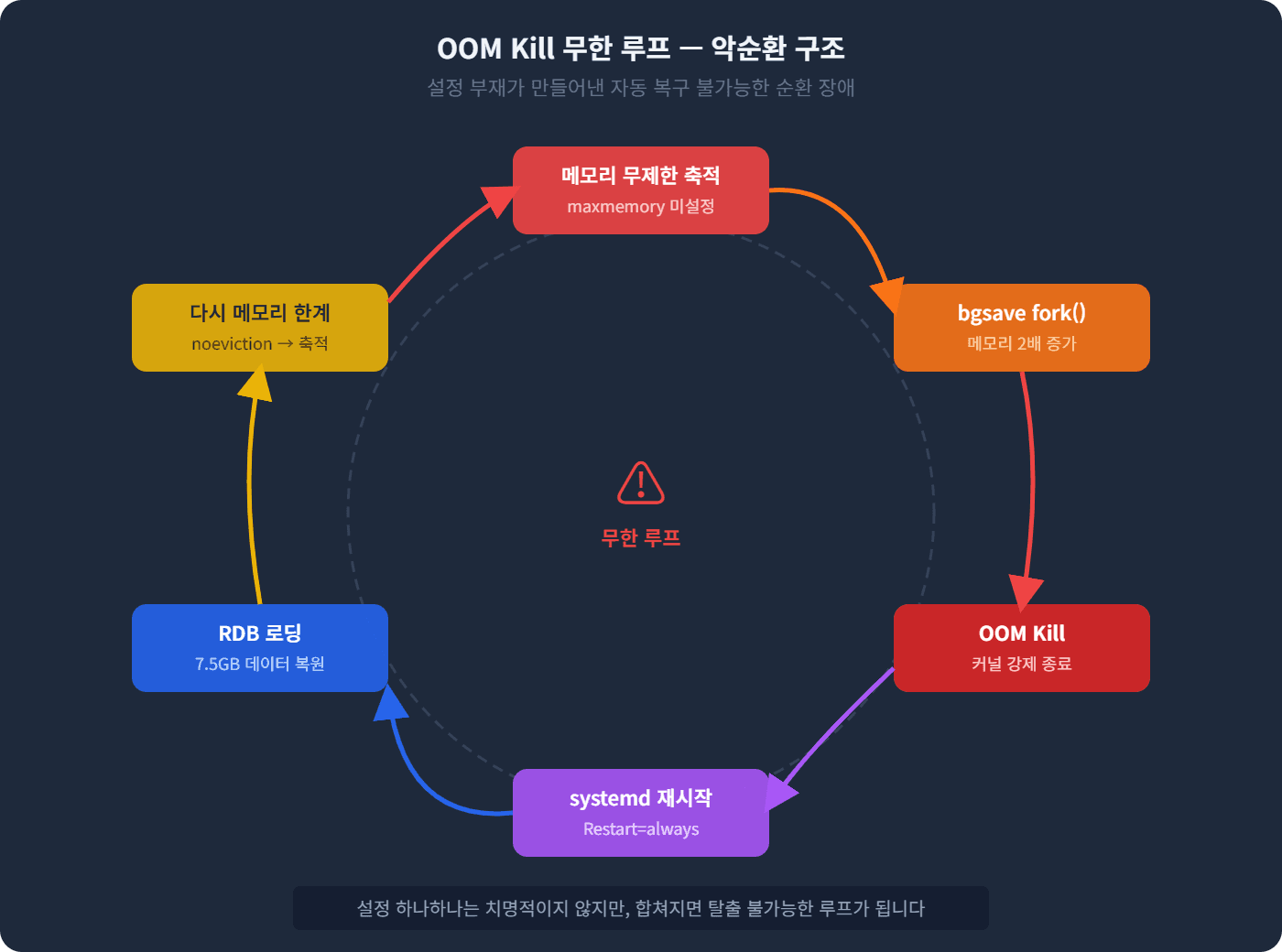
정리하면 이런 순환이었습니다:
Redis 시작 → RDB 로딩 시작
메모리 사용량 급증 → 서버 전체 메모리 소진
커널 OOM Killer가 Redis 강제 종료
systemd가 Restart=always로 자동 재시작
1번으로 돌아감 → 무한 반복
원인 분석 — redis.conf를 열어보니
증상을 확인한 뒤, 근본 원인을 찾기 위해 Redis 설정 파일을 열어봤습니다. 문제는 한 가지가 아니라 세 가지 설정이 합쳐져서 최악의 시나리오를 만들고 있었습니다.
(1) maxmemory 미설정
$ grep "^maxmemory" /etc/redis/redis.conf
(결과 없음)
maxmemory 설정이 아예 없었습니다. Redis의 기본값은 0, 즉 메모리 제한 없음입니다. 이 상태에서 Redis는 물리 메모리가 허용하는 한 계속 데이터를 쌓습니다. 8GB 서버에서 Redis가 7.5GB 이상을 사용한 이유가 여기에 있었습니다.
캐시 용도의 Redis라면, 서버 전체 메모리의 60~75% 수준으로 maxmemory를 설정하는 것이 일반적인 권장사항입니다. 8GB 서버라면 5~6GB 정도가 적절합니다. 나머지는 OS, 기타 프로세스, 그리고 Redis 자체의 오버헤드(자료구조 메타데이터, 클라이언트 버퍼 등)를 위해 남겨두어야 합니다.
(2) maxmemory-policy 기본값 noeviction
$ grep "^maxmemory-policy" /etc/redis/redis.conf
(결과 없음)
maxmemory-policy도 설정되어 있지 않았습니다. 기본값은 noeviction으로, 메모리가 가득 차면 기존 키를 삭제하지 않고 새로운 쓰기 요청을 거부합니다. 캐시 용도에서는 최악의 정책입니다.
정책 | 동작 | 적합한 상황 |
|---|---|---|
noeviction | 메모리 가득 차면 쓰기 거부 (에러 반환) | 데이터 손실이 절대 불가한 경우 (캐시에는 부적합) |
allkeys-lru | 모든 키 중 가장 오래 사용되지 않은 키 삭제 | 일반적인 캐시 용도 (가장 많이 사용) |
allkeys-lfu | 모든 키 중 가장 사용 빈도가 낮은 키 삭제 | 접근 빈도 기반 캐시 |
volatile-lru | TTL이 설정된 키 중 LRU 삭제 | 일부 키만 만료 대상인 경우 |
volatile-lfu | TTL이 설정된 키 중 LFU 삭제 | TTL 키의 빈도 기반 삭제 |
volatile-ttl | TTL이 가장 짧은 키부터 삭제 | 만료 임박 키 우선 삭제 |
allkeys-random | 모든 키 중 무작위 삭제 | 균등 접근 패턴일 때 |
volatile-random | TTL 키 중 무작위 삭제 | TTL 키의 무작위 삭제 |
캐시 용도라면 allkeys-lru가 대부분의 상황에서 최선의 선택입니다. 오래 사용하지 않은 키를 자동으로 삭제해서 새로운 데이터를 위한 공간을 확보하기 때문입니다.
(3) save 설정 활성 — bgsave의 숨은 메모리 폭탄
$ grep "^save" /etc/redis/redis.conf
save 900 1
save 300 10
save 60 10000
Redis의 기본 RDB 스냅샷 설정이 그대로 활성화되어 있었습니다. 이 설정은 Redis가 주기적으로 bgsave(백그라운드 저장)를 실행해서 메모리 데이터를 디스크에 RDB 파일로 저장하도록 합니다.
문제는 bgsave의 동작 방식에 있습니다. bgsave는 fork() 시스템 콜을 사용해서 자식 프로세스를 만들고, 자식 프로세스가 RDB 파일을 기록합니다. fork() 시점에 부모 프로세스의 메모리 페이지를 공유하지만(Copy-on-Write), 부모 프로세스에서 쓰기가 발생하면 해당 페이지가 복사됩니다.
쓰기가 많은 환경에서는 fork() 후 메모리 사용량이 최대 2배까지 증가할 수 있습니다. 7.5GB를 사용하던 Redis가 bgsave를 시작하면, 순간적으로 15GB까지 메모리가 필요해질 수 있다는 뜻입니다. 8GB 서버에서 이건 확정적인 OOM Kill입니다.
게다가 디스크를 확인해 보니:
$ ls -la /var/lib/redis/temp-*.rdb | wc -l
51
$ du -sh /var/lib/redis/temp-*.rdb
59G total
bgsave가 실패할 때마다 남긴 임시 RDB 파일이 51개, 총 59GB가 쌓여 있었습니다. 디스크 공간까지 압박하고 있었던 것입니다.
악순환의 전체 그림
세 가지 설정 문제가 합쳐져 만들어낸 악순환의 전체 그림은 다음과 같습니다:
maxmemory 미설정 → Redis가 서버 메모리 거의 전부를 사용 (7.5GB/8GB)
noeviction 정책 → 메모리가 가득 차도 기존 키를 삭제하지 않음 → 쓰기 실패가 쌓이지만 메모리는 줄지 않음
save 설정 활성 → 주기적으로 bgsave 시도 → fork()로 메모리 사용량 급증
OOM Kill → 커널이 Redis 강제 종료
Restart=always → systemd가 자동 재시작 → RDB 파일(7.5GB) 로딩 시작
RDB 로딩 완료 → 다시 메모리 가득 참 → 2번으로 돌아감
설정 하나하나는 치명적이지 않을 수 있지만, 세 가지가 합쳐지면 스스로 빠져나올 수 없는 무한 루프가 됩니다.
RDB 로딩의 함정
여기서 한 가지 중요한 사실을 짚어야 합니다. maxmemory를 설정하면 되는 거 아니야?라고 생각할 수 있는데, RDB 로딩 중에는 상황이 다릅니다.
Redis는 RDB 파일을 로딩하는 동안에는 maxmemory 제한을 적용하지 않습니다. 즉, maxmemory를 5GB로 설정해도 RDB 파일에 7.5GB의 데이터가 들어 있으면 로딩 중에 7.5GB까지 메모리를 사용합니다. 로딩이 완료된 후에야 maxmemory 정책에 따라 초과분을 삭제하기 시작합니다.
이 때문에 단순히 maxmemory만 설정하고 Redis를 재시작하면, RDB 로딩 중에 또다시 OOM Kill을 당할 수 있습니다. 이 함정을 인지하고 있어야 올바른 순서로 조치할 수 있습니다.
핵심: maxmemory 설정 변경 후 Redis를 재시작할 때, 기존 RDB 파일의 크기가 새로운 maxmemory보다 크다면, RDB 파일을 삭제하거나 이름을 변경한 뒤 재시작해야 안전합니다.
해결 과정
원인을 파악한 뒤, 다음 순서로 조치를 진행했습니다. 순서가 중요합니다.
(1) Redis 중지 및 dump.rdb 백업
$ systemctl stop redis
$ cp /var/lib/redis/dump.rdb /var/lib/redis/dump.rdb.bak.$(date +%Y%m%d)
먼저 Redis를 완전히 중지합니다. 무한 루프를 끊는 첫 번째 단계입니다. 기존 RDB 파일은 혹시 필요할 수 있으니 백업해 둡니다. 캐시 데이터라서 날려도 되지만, 습관적으로 백업하는 것이 좋습니다.
(2) maxmemory 설정
# /etc/redis/redis.conf
maxmemory 5gb
서버 메모리 8GB의 약 62%인 5GB로 설정했습니다. OS와 기타 프로세스, Redis 자체 오버헤드를 고려한 값입니다.
(3) maxmemory-policy allkeys-lru
# /etc/redis/redis.conf
maxmemory-policy allkeys-lru
캐시 용도이므로 allkeys-lru로 설정합니다. 메모리가 가득 차면 가장 오래 사용되지 않은 키부터 자동으로 삭제됩니다.
(4) save 비활성화
# /etc/redis/redis.conf
save ""
캐시 용도의 Redis에는 RDB 스냅샷이 필요하지 않습니다. save ""로 bgsave를 완전히 비활성화합니다. 이렇게 하면 fork()로 인한 메모리 폭증 위험이 사라집니다.
(5) temp-*.rdb 삭제
$ rm /var/lib/redis/temp-*.rdb
$ rm /var/lib/redis/dump.rdb
실패한 bgsave의 잔재인 임시 RDB 파일 51개(59GB)를 삭제합니다. 기존 dump.rdb도 삭제하는데, RDB 로딩의 함정에서 설명한 것처럼 로딩 중 maxmemory를 초과하는 것을 방지하기 위해서입니다. 캐시 데이터는 원본 DB에서 다시 채워지므로 문제없습니다.
(6) 조치 후 확인
$ systemctl start redis
$ redis-cli PING
PONG
$ redis-cli INFO memory | grep -E "used_memory_human|maxmemory_human|maxmemory_policy"
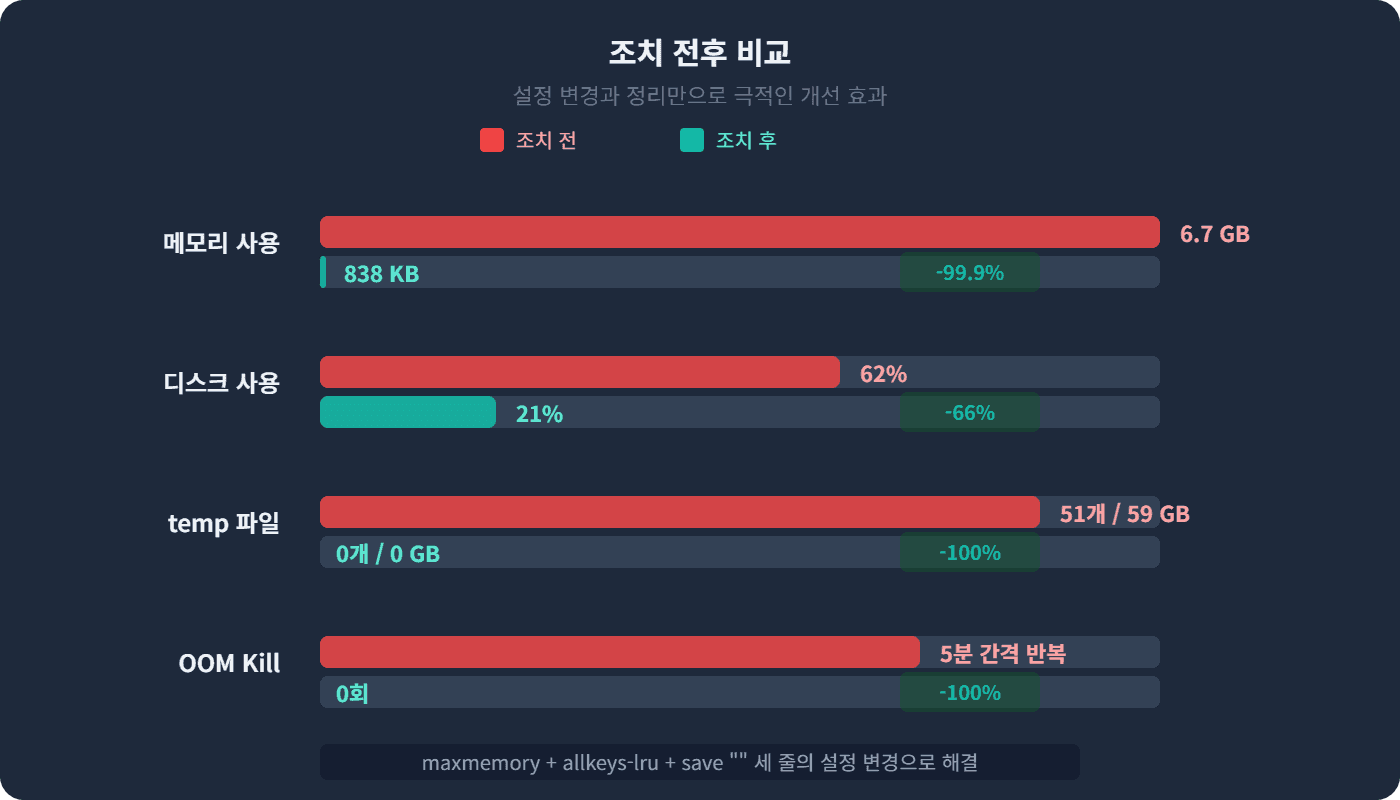
used_memory_human:1.24M
maxmemory_human:5.00G
maxmemory_policy:allkeys-lru
Redis가 정상적으로 시작되었습니다. RDB 파일이 없으므로 빈 상태에서 시작하여 메모리 사용량이 최소화되어 있고, maxmemory와 eviction 정책이 올바르게 적용된 것을 확인할 수 있습니다.
이후 몇 시간 동안 모니터링한 결과, 캐시 데이터가 점진적으로 채워지면서 메모리 사용량이 증가했지만, 5GB 제한 내에서 allkeys-lru 정책에 의해 안정적으로 관리되었습니다. OOM Kill은 더 이상 발생하지 않았습니다.
추가로 발견된 문제들
OOM Kill 문제를 해결하는 과정에서 몇 가지 추가 문제도 발견되었습니다.
Swap 100% 사용: OOM Kill이 반복되는 동안 swap 영역도 가득 찬 상태였습니다. Redis에서는 swap 사용 자체가 성능에 치명적이므로,
vm.swappiness=1로 설정하여 swap 사용을 최소화했습니다.커널 파라미터 경고: Redis 로그에
WARNING overcommit_memory is set to 0!경고가 지속적으로 출력되고 있었습니다.vm.overcommit_memory=1로 설정하여 fork() 시 메모리 할당이 거부되지 않도록 조치했습니다.보안 설정 부재:
requirepass가 설정되어 있지 않아, 서버에 접근 가능한 누구나 Redis 명령을 실행할 수 있는 상태였습니다. 인증 비밀번호를 설정하고,bind설정을 확인하여 불필요한 네트워크 노출을 차단했습니다.
Redis 운영에서 흔히 놓치는 설정들
이번 사례를 계기로, Redis 운영에서 흔히 놓치지만 반드시 챙겨야 할 설정들을 정리합니다.
maxmemory와 eviction
반드시 maxmemory를 설정하세요. 기본값 0(무제한)은 프로덕션 환경에서 사용하면 안 됩니다.
서버 전체 메모리의 60~75%를 권장합니다. 나머지는 OS, 기타 프로세스, Redis 오버헤드를 위해 남겨둡니다.
캐시 용도라면 allkeys-lru가 대부분의 상황에서 최선입니다.
세션 스토어처럼 모든 키에 TTL이 있다면 volatile-lru도 고려할 수 있습니다.
save/bgsave
캐시 전용 Redis라면 save ""로 RDB 스냅샷을 비활성화하세요.
영속성이 필요하다면 bgsave 대신 AOF(Append Only File)를 고려하세요. AOF는 fork()가 필요하지 않아 메모리 부담이 적습니다.
bgsave를 사용해야 한다면, maxmemory를 서버 메모리의 45% 이하로 설정하여 fork() 시 메모리 2배 증가에 대비하세요.
KEYS 명령 금지
프로덕션 환경에서 KEYS * 명령은 절대 사용하지 마세요. 전체 키 스캔으로 Redis가 블로킹되어 서비스 장애를 유발합니다.
대신 SCAN 명령을 사용하세요. 커서 기반으로 점진적으로 키를 조회하므로 블로킹이 발생하지 않습니다.
rename-command KEYS ""설정으로 KEYS 명령 자체를 비활성화하는 것을 권장합니다.
INFO 모니터링
redis-cli INFO memory로 used_memory, used_memory_rss, mem_fragmentation_ratio를 주기적으로 확인하세요.mem_fragmentation_ratio가 1.5 이상이면 메모리 단편화가 심한 상태입니다. Redis 4.0 이상에서는
activedefrag yes로 자동 단편화 해소를 활성화할 수 있습니다.redis-cli INFO stats에서 evicted_keys 수치가 급증하면 메모리 부족 신호이므로, maxmemory 증설을 검토해야 합니다.
연결 수 관리
maxclients 설정을 확인하세요. 기본값은 10000이지만, 연결 수가 과도하면 메모리 사용량이 증가합니다.
timeout 설정으로 유휴 연결을 자동으로 끊어주세요. 기본값 0(무제한)은 좀비 연결이 쌓이는 원인이 됩니다. 300(5분) 정도를 권장합니다.
애플리케이션 측에서도 커넥션 풀을 사용하여 연결 수를 관리하는 것이 중요합니다.
이번 장애의 근본 원인은 결국 설정을 하지 않은 것이었습니다. Redis를 설치하고 기본 설정 그대로 프로덕션에 투입한 것이 모든 문제의 시작이었죠.
Redis는 기본 설정이 개발/테스트 환경에 맞춰져 있습니다. maxmemory 무제한, noeviction 정책, RDB 스냅샷 활성화 — 이 조합은 소규모 테스트에서는 문제가 없지만, 프로덕션 트래픽을 받는 순간 시한폭탄이 됩니다.
Redis 설치 후 프로덕션에 투입하기 전에, 최소한 maxmemory, maxmemory-policy, save 설정 세 가지는 반드시 용도에 맞게 변경해야 합니다. 이 세 줄의 설정이 새벽 3시의 긴급 전화를 예방합니다.
이것만 기억하세요
① maxmemory는 반드시 설정하세요. 기본값 0(무제한)은 프로덕션에서 OOM Kill의 직접적인 원인입니다. ② 캐시 용도라면 allkeys-lru를 사용하세요. noeviction 기본값은 캐시에 최악의 정책입니다. ③ 캐시 Redis에서는 save ""로 RDB를 끄세요. bgsave의 fork()는 메모리를 최대 2배로 증가시킵니다. ④ RDB 로딩 중에는 maxmemory가 적용되지 않습니다. 재시작 시 기존 RDB 크기를 반드시 확인하세요. ⑤ Redis 기본 설정은 프로덕션용이 아닙니다. 설치 후 반드시 환경에 맞게 변경한 뒤 투입하세요.
자주 묻는 질문(FAQ)
Q. Redis OOM Kill이 발생하면 데이터가 유실되나요?
네, OOM Kill은 커널이 프로세스를 강제 종료하는 것이므로 메모리에 있던 데이터 중 디스크에 저장되지 않은 부분은 유실됩니다. RDB 스냅샷이나 AOF가 활성화되어 있다면 마지막 저장 시점까지의 데이터는 복구할 수 있지만, 캐시 용도라면 원본 DB에서 다시 채워지므로 유실 자체는 큰 문제가 되지 않습니다. 진짜 문제는 OOM Kill이 반복되면서 서비스 전체에 영향을 주는 것입니다.
Q. maxmemory를 설정하면 OOM Kill을 완전히 막을 수 있나요?
대부분의 경우 막을 수 있지만, 100%는 아닙니다. maxmemory는 Redis가 관리하는 데이터 크기만 제한하며, 클라이언트 출력 버퍼, Lua 스크립트 메모리, 복제 백로그 등은 별도로 메모리를 사용합니다. 또한 bgsave의 fork() 메모리 증가분도 maxmemory에 포함되지 않습니다. 따라서 maxmemory는 서버 전체 메모리보다 충분히 낮게 설정하고, 모니터링을 병행하는 것이 안전합니다.
Q. bgsave 대신 AOF를 사용하면 메모리 문제가 해결되나요?
AOF는 쓰기 명령을 로그 형태로 기록하므로 fork()가 필요하지 않아 메모리 부담이 훨씬 적습니다. 다만 AOF rewrite 시에는 fork()가 발생하므로 완전히 자유롭지는 않습니다. 캐시 전용 Redis라면 영속성 자체를 비활성화(save "", appendonly no)하는 것이 가장 깔끔한 해결책입니다.
Q. Redis가 사용하는 메모리를 실시간으로 모니터링하려면 어떻게 해야 하나요?
redis-cli INFO memory 명령으로 used_memory, used_memory_rss, maxmemory 등을 확인할 수 있습니다. 자동 모니터링이 필요하다면 Prometheus + Redis Exporter 조합이나, Grafana 대시보드를 구성하는 것을 권장합니다. 최소한 used_memory_rss가 서버 메모리의 80%를 넘으면 경보가 발생하도록 설정해 두는 것이 좋습니다.




