
매니지드 없는 RabbitMQ, NHN Cloud에서 HA로 직접 짓기

🤖 AI Summary
메시지 브로커를 도입할 때 흔히 "매니지드로 쓸 수 있나"를 먼저 묻습니다. 그런데 RabbitMQ는 완전관리형으로 제공되는 경우가 드뭅니다. 메모리에 큐를 상주시키는 구조, 공유 비밀(Erlang Cookie) 기반의 클러스터 신뢰, 상태형 저장 같은 특성 때문에 클라우드가 관리형으로 내놓기 까다롭기 때문이죠. 그래서 직접 운영이 기본입니다. 이 글은 NHN Cloud의 VM과 Load Balancer로 3노드 고가용성 클러스터를 짓는 구조를 다룹니다. 핵심은 Quorum Queue입니다. Raft 합의로 과반수 노드에 복제가 끝나야 발행을 확인하므로, 한 노드가 죽어도 메시지가 유실되지 않습니다. 다만 두 노드가 동시에 죽으면 과반수를 잃어 큐가 멈추는데, 이는 일관성을 위한 의도된 동작입니다. 그리고 진짜 고가용성은 구성이 아니라 실제 VM 전원을 끄는 장애 테스트로 증명됩니다.
블로그 목차
RabbitMQ는 왜 매니지드가 드문가
Apache Kafka가 상대적으로 매니지드 선택지가 많은 편인 반면, RabbitMQ는 클라우드가 완전관리형으로 직접 제공하는 경우가 드뭅니다. 국내 클라우드에서도 RabbitMQ를 별도 관리형으로 제공하기보다, 고객이 VM 위에 직접 구성하는 방식이 일반적입니다. 이유는 RabbitMQ의 구조에 있습니다.
메모리 집약적: 큐의 메시지와 메타데이터를 메모리에 상주시키고, 일정 한도를 넘으면 발행을 일시 차단합니다. 멀티테넌트 환경에서 자원 보장과 격리가 어렵습니다.공유 비밀 기반 클러스터: 노드 간 신뢰가 모든 노드가 같은 Erlang Cookie를 가져야 하는 구조라, 수많은 테넌트의 클러스터를 안전하게 격리하기 까다롭습니다.상태형(stateful): 큐 데이터가 각 노드의 로컬에 저장되어, 탄력적 증설이나 무중단 이전이 상대적으로 까다롭습니다.
이런 이유로 RabbitMQ는 직접 운영(self-hosted)이 기본인 소프트웨어로 남아 있습니다. 뒤집어 말하면, 메모리와 디스크 같은 핵심 자원을 잘 관리하면 NHN Cloud 환경에서도 엔터프라이즈급 고가용성을 만들 수 있다는 뜻이기도 합니다.
NHN Cloud에서 짓는 HA 구조
구성의 뼈대는 단순합니다. RabbitMQ 노드 3개를 외부에서 직접 접근할 수 없는 Private Subnet에 두고, 클라이언트는 Load Balancer의 VIP를 통해서만 메시지를 주고받습니다. 운영자의 접속은 Bastion VM을 거치는 방식으로만 허용합니다.
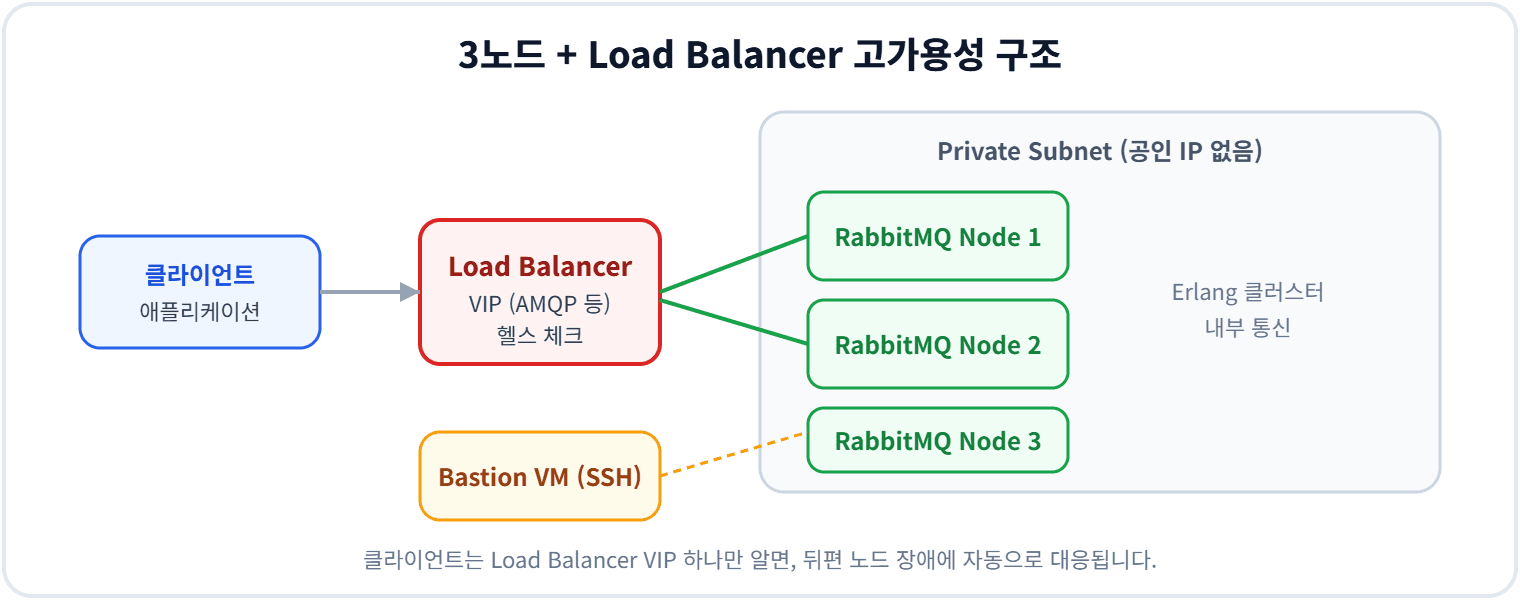
이 구조의 이점은 두 가지입니다. 노드에 공인 IP를 두지 않아 외부 공격 면적이 줄고, 클라이언트가 VIP 하나만 알면 노드 장애에 자동으로 대응됩니다. NHN Cloud Load Balancer는 AMQP 같은 TCP 서비스를 분산하고, 헬스 체크로 죽은 노드를 트래픽에서 빼줍니다.
Quorum Queue: Raft로 무손실을 보장한다
고가용성의 진짜 핵심은 큐 타입입니다. RabbitMQ는 비교적 최신 버전에서 Quorum Queue를 권장하는데, 이것이 메시지 무손실을 떠받치는 토대입니다. (RabbitMQ와 Erlang의 버전 호환은 공식 호환성 매트릭스를 확인해 맞추는 것이 먼저입니다.)
Quorum Queue는 Raft 합의 알고리즘을 기반으로 Leader 1개와 Follower로 구성됩니다. 핵심 동작은 이렇습니다.
Publisher Confirm 보장: Leader가 메시지를 받아과반수 노드에 복제가 끝난 뒤에야발행자에게 확인을 보냅니다. 확인을 받은 메시지는 과반수가 살아 있는 한 유실되지 않습니다.자동 Leader 재선출: Leader가 멈추면 남은 Follower 중 하나가 Raft 선거로 새 Leader가 됩니다.변경분 동기화: 잠시 빠졌던 노드가 다시 합류하면, 그 사이 쌓인 부분만 동기화해 빠르게 정상으로 돌아옵니다.

운영을 가르는 몇 가지 원칙
구성보다 운영에서 사고가 납니다. 다음 원칙이 클러스터의 수명을 좌우합니다.
한 번에 한 대씩: 위에서 봤듯 2노드 동시 정지는 큐를 멈춥니다. 패치나 설정 변경은 순차적으로, 한 노드를 올린 뒤 재합류를 확인하고 다음으로 넘어갑니다. 이때의 중단은 재시작에 따른 일시 중단이며, 두 노드가 디스크째 영구히 손실되면 해당 큐는 복구가 어렵습니다. 그래서 노드를 서로 다른 장애 도메인에 두어 동시 영구 손실 확률을 낮추는 설계도 중요합니다.소수파 일시정지(pause_minority): 네트워크가 갈렸을 때 고립된 소수 노드가 스스로 멈추도록 설정해, 양쪽이 따로 도는 split-brain을 막습니다.메모리·디스크 워터마크: RabbitMQ는 메모리가 한도를 넘으면 발행을 차단하고, 디스크 여유가 기준 이하로 떨어지면 클러스터 전체의 발행을 막습니다. 그래서 메모리와 디스크 모니터링이 필수이고, Quorum Queue는 공식 문서가 권고하는 대로 WAL 크기 한도의 약 3배 정도 여유 메모리를 확보해 두는 것이 안전합니다.
설정값(메모리 워터마크 비율, 디스크 한도 등)은 노드의 사양과 RabbitMQ 버전에 따라 달라지므로, 운영 전에 사용 중인 버전의 공식 문서로 한 번 맞춰 두는 것이 좋습니다.
진짜 HA는 테스트로 증명한다
고가용성 클러스터를 구성했다고 해서 곧바로 "HA가 된다"고 말하기는 어렵습니다. 실제 장애 상황에서 예상대로 동작하는지 확인하는 테스트가 운영 신뢰성의 핵심입니다.
여기서 중요한 점이 있습니다. RabbitMQ 프로세스를 멈추는 테스트와, 실제 VM의 전원을 끄는 테스트는 차원이 다릅니다. 후자라야 NHN Cloud Load Balancer의 헬스 체크와 트래픽 전환, 노드의 자동 재합류까지 전체 스택을 검증할 수 있습니다. 실무에서는 다음을 순서대로 확인합니다.
기본 연결성: VIP를 통한 발행과 소비가 정상인지.랜덤 노드 전원 종료: 한 노드의 VM을 꺼서 Load Balancer가 해당 노드를 트래픽에서 빼고, 남은 2노드로 메시지가 계속 흐르는지.자동 복구: 껐던 VM을 다시 켰을 때 사람 개입 없이 RabbitMQ가 재시작·재합류하고 변경분이 동기화되는지.Leader 노드 종료: 큐의 Leader 노드를 꺼도 새 Leader가 선출되며 확인받은 메시지가 유실되지 않는지.정리·최종 확인: 모든 노드와 Load Balancer 멤버가 정상으로 돌아왔는지.
이 과정을 통과해야 비로소 VM 장애, Leader 장애, 자동 복구를 모두 처리하는 진짜 고가용성입니다. 테스트를 거치지 않은 HA는 "이론적 HA"에 머뭅니다.
이것만 기억하세요
RabbitMQ는 완전관리형이 드물어 직접 운영이 기본이고, NHN Cloud에서는 3노드 + Load Balancer로 HA를 짓습니다. 핵심은 Quorum Queue(Raft)입니다. 과반수 복제 후에 발행을 확인하므로 한 노드가 죽어도 무손실이지만, 두 노드가 동시에 죽으면 과반수를 잃어 큐가 멈추는 것은 의도된 동작이라 점검은 한 번에 한 대씩 해야 합니다. 그리고 진짜 HA는 구성이 아니라 실제 VM 전원을 끄는 장애 테스트로 증명됩니다.
자주 묻는 질문 (FAQ)
Q. RabbitMQ는 왜 매니지드 서비스가 드문가요?
큐의 메시지와 메타데이터를 메모리에 상주시키는 메모리 집약적 구조이고, 노드 간 신뢰가 공유 비밀(Erlang Cookie)에 기반하며, 큐 데이터가 각 노드 로컬에 저장되는 상태형 소프트웨어예요. 이런 특성이 멀티테넌트 환경의 자원 격리와 운영을 어렵게 해서, 클라우드가 완전관리형으로 내놓기 까다롭습니다. 그래서 직접 운영이 기본이고, 클라우드에서도 VM 위에 직접 구성하는 경우가 많아요.
Q. Quorum Queue는 어떻게 메시지 손실을 막나요?
Raft 합의를 기반으로 Leader와 Follower로 구성돼요. 발행자가 보낸 메시지는 Leader가 받아 과반수 노드에 복제가 끝난 뒤에야 확인(Publisher Confirm)을 보냅니다. 그래서 확인받은 메시지는 과반수가 살아 있는 한 유실되지 않아요. Leader가 멈추면 남은 Follower 중 하나가 자동으로 새 Leader가 됩니다.
Q. 노드 2개가 동시에 죽으면 어떻게 되나요?
3노드에서 과반수는 2예요. 1개가 죽어도 나머지 2개가 과반수를 유지해 큐는 계속 동작합니다. 반대로 2개가 동시에 죽으면 과반수를 잃어 큐가 일시 중단되는데, 이건 버그가 아니라 데이터 일관성을 우선하는 의도된 동작이에요. 그래서 재시작·패치는 반드시 한 번에 한 대씩 진행하고, 두 대를 동시에 멈추지 않아야 합니다.
Q. HA로 구성했다면 그걸로 끝인가요?
구성만으로 고가용성이 보장되진 않아요. 실제 장애에서 예상대로 동작하는지 테스트로 검증해야 합니다. 특히 프로세스를 멈추는 수준이 아니라 실제 VM 전원을 끄는 테스트라야 로드 밸런서 헬스 체크와 트래픽 전환, 자동 재합류까지 전체 스택을 확인할 수 있어요. 테스트를 거치지 않은 HA는 이론적 HA에 머뭅니다.
Q. RabbitMQ HA를 직접 운영하기 부담되면 어떻게 하나요?
메모리·디스크 워터마크 관리, 클러스터 구성과 장애 대응, 무중단 롤링 재시작 같은 운영 부담이 큽니다. 직접 운영이 어렵다면 NHN Cloud 환경에 익숙한 파트너와 구축부터 운영, 장애 대응까지 함께 설계하는 방법이 있어요. 스피디는 NHN Cloud 플래티넘 파트너로서 이런 구성을 함께 점검합니다.



