
한 줄의 자동화가 Railway를 8시간 멈췄습니다, GCP 계정 자동 정지로 본 SaaS control plane 위험

🤖 AI Summary
2026년 5월 19일 22시 20분(UTC), Google Cloud가 자동화된 절차로 Railway의 production 계정을 잘못된 상태인 suspended로 변경했습니다. 계정 접근 자체는 22시 29분(UTC)에 9분 만에 복구됐지만, persistent disk·compute·networking 순서로 데이터 plane이 단계적으로 살아나며 영향이 완전히 종료된 monitoring 진입 시점은 5월 20일 06시 14분(UTC), 한국 시각으로는 5월 20일 07시 20분부터 15시 14분까지 약 8시간 동안 Railway 대시보드, API, 네트워크 인프라, GCP 호스팅 컴퓨트가 영향을 받았고 사용자는 503 에러와 no healthy upstream 메시지를 만나며 로그인 자체가 불가능했어요. Railway는 향후 의존성을 제거하고 true mesh 구조로 옮기겠다고 밝혔고, 하이 어베일러빌리티 데이터베이스 샤드를 AWS와 Metal까지 확장하겠다고 발표했습니다. 이 사건이 한국 SaaS에 던지는 질문은 분명합니다. control plane이 한 클라우드 계정 위에 묶여 있다면, 우리도 똑같이 자동화 정책 한 줄에 흔들릴 수 있다는 점이죠.
블로그 목차
오전 7시, 503 에러 알람이 쏟아지는 슬랙 채널을 보며 일과를 시작한 운영팀이 있었습니다. 평소 가용성을 책임지던 클라우드의 계정이 자동화 정책에 의해 정지됐다는 사실을 8시간 뒤에야 알게 됐죠. 이번 글에서는 그 8시간 동안 Railway에 무슨 일이 있었는지, 그리고 한국 SaaS·핀테크·이커머스 운영팀이 같은 사건을 만나지 않으려면 무엇을 점검해야 하는지 1차 출처 기준으로 정리합니다.
5월 19일 22시 20분, Railway가 GCP에서 자동으로 정지됐습니다
Railway 운영팀에게 5월 19일 화요일 밤은 평범하지 않았습니다. 협정세계시(UTC) 기준 22시 20분, Google Cloud가 Railway의 production 계정을 자동화된 절차의 일부로 잘못된 상태인 suspended로 변경했습니다. 한국 시각으로는 20일 수요일 오전 7시 20분이었고, 이때부터 Railway 사용자들은 사이트에 접속할 수 없었습니다.
Railway가 공식 incident report에서 밝힌 영향 범위는 명확합니다. 대시보드, API, 네트워크 인프라 일부, 그리고 Google Cloud에 호스팅된 컴퓨트 인프라 전체였습니다. 사용자에게 가장 먼저 보인 화면은 503 에러였고, no healthy upstream과 unconditional drop overload 메시지가 함께 떴습니다. 로그인 자체가 불가능했습니다.
"Users immediately experienced 503 errors on the dashboard and API, including 'no healthy upstream' and 'unconditional drop overload' messages, and were unable to log in." (Railway 공식 incident report, 2026-05-20)
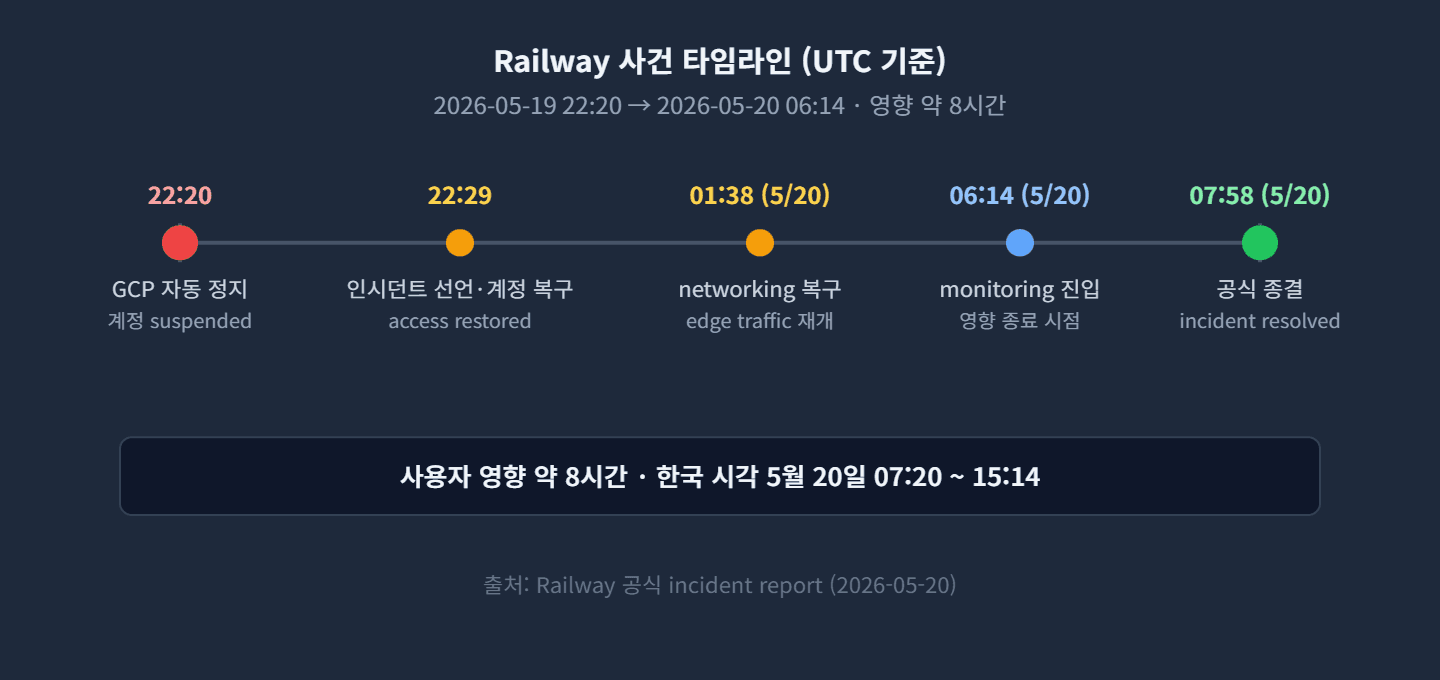
계정 정지 상태 자체는 22시 29분(UTC)에 9분 만에 빠르게 복구됐지만, persistent disk(23:09), compute instance(01:30), networking(01:38) 순서로 데이터 plane이 단계적으로 살아났고, monitoring 단계로 옮겨간 시점은 다음 날 6시 14분(UTC), 한국 시각으로는 5월 20일 오후 3시 14분이었습니다. 자동 정지부터 사용자 영향이 완전히 종료되기까지 약 8시간이 걸렸어요.
8시간 정지가 보여준 것은 control plane 의존의 SPOF였습니다
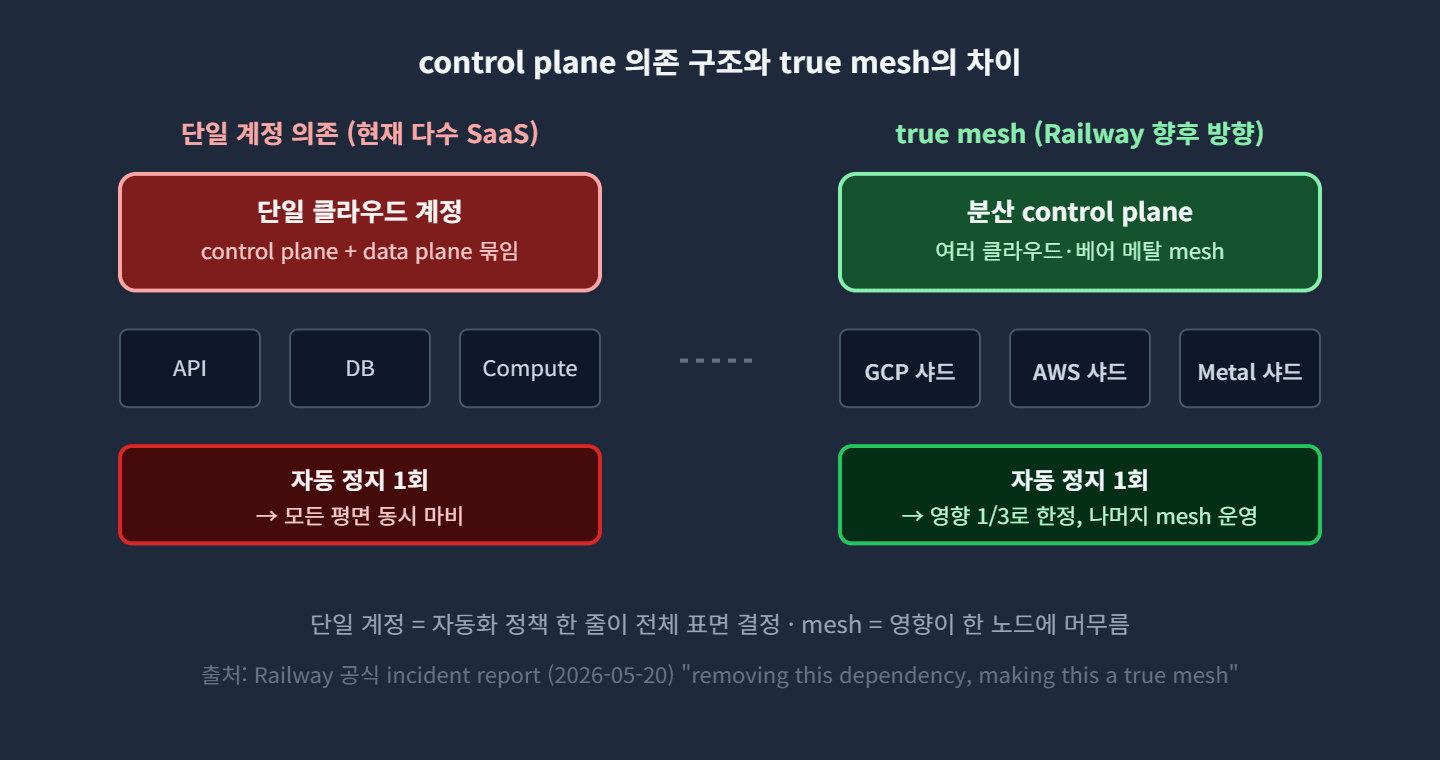
이번 사건이 단순한 한 회사 사고로 끝나지 않는 이유는 영향 범위에 있습니다. Railway는 사실 이미 Metal·AWS·GCP 세 환경을 묶은 멀티 클라우드 mesh 위에서 운영되고 있었어요. 그런데도 대시보드, API, 라우팅 메타데이터를 처리하는 network control plane API가 Google Cloud 단일 호스팅이었기 때문에, 그 계정 하나가 정지되자 멀티 클라우드 mesh 위의 모든 표면이 동시에 영향을 받았습니다.
The Register가 보도한 Railway Solutions Engineer Angelo Saraceno의 발언은 이 구조를 단번에 정리합니다.
"Our customers don't care if it is Google. We have to own our uptime." (Angelo Saraceno, Solutions Engineer at Railway, The Register 2026-05-20 보도)
고객 입장에서 장애 원인이 Google이든 Railway든 관계없습니다. 보이는 결과는 똑같이 503입니다. 운영을 책임지는 쪽이 책임을 그대로 떠안는다는 뜻이고, 이는 한국 SaaS·핀테크·이커머스 운영팀도 똑같이 받아드는 질문입니다.
The Register는 같은 기사에서 Railway가 Google Cloud에 연간 eight-figure sum, 즉 8자리 금액을 지출하는 대형 고객이라고 명시했습니다. 큰 매출을 내는 고객이라도 자동화 정책 분류가 잘못되면 똑같이 영향을 받는다는 점이 이번 사건의 메시지였습니다.
자동화된 정책 한 줄이 멀티 테넌트 전체를 끌어내리는 구조
왜 자동 정지 한 건이 8시간 가용성 사고로 번질까요. control plane이라는 개념을 살펴보면 답이 보입니다.
일반적으로 클라우드 아키텍처는 두 평면으로 나뉩니다. data plane은 실제 트래픽을 처리하는 컴퓨트, 스토리지, 네트워크 회선이고, control plane은 그 자원의 상태와 권한을 관리하는 계정, API, 메타데이터, 정책 엔진입니다. data plane을 여러 리전과 가용영역으로 분산해 두어도, control plane이 한 클라우드 계정 위에 있으면 그 계정이 막히는 순간 분산은 의미가 없습니다.
Railway 보고서가 밝힌 복구 순서가 그 구조를 그대로 보여 줍니다. 정지가 풀린 뒤에도 persistent disk가 먼저 마운트되고, 그 위에 compute instance가 다시 떠야 하며, 마지막으로 networking이 정상화되어야 사용자 요청이 흐릅니다. 한 번에 살아나는 것이 아니라 control plane의 메타데이터를 따라 순차 복구되는 구조입니다.
이번 사건의 가장 흥미로운 부분은 cascade 메커니즘입니다. Railway의 edge proxies는 GCP에 호스팅된 network control plane API에서 라우팅 테이블을 받아 캐시해두는 구조였어요. 계정 정지 직후에는 그 캐시가 살아 있어 Metal·AWS에 있던 워크로드는 정상 응답했습니다. 그러나 정지 약 15분 뒤인 22시 35분(UTC) 무렵 캐시가 만료되자 edge가 더 이상 라우트를 풀지 못했고, GCP 바깥의 Metal·AWS 워크로드까지 404를 반환했죠. control plane이 한 곳에 묶여 있으면 데이터가 다른 클라우드에 분산돼 있어도 똑같이 멈춘다는 점을 정확하게 보여 준 메커니즘입니다.
The Register는 같은 기사에서 2024년 Google Cloud가 호주 연금펀드 UniSuper의 인프라 전체를 삭제한 사건을 함께 언급했습니다. 이 사건도 사람이 결정한 것이 아니라 운영·자동화 절차가 의도와 다르게 작동한 케이스였습니다. 한 클라우드 계정 안에 자원 메타데이터가 묶여 있을 때, 자동화 정책 한 줄이 그 회사의 운영 표면을 통째로 흔들 수 있다는 패턴이 반복되고 있습니다.
한국 SaaS가 지금 점검할 control plane SPOF 5지점
이번 글의 5지점은 SPOF라는 단어를 쓰는 다른 글들과 한 가지가 다릅니다. 일반적으로 SPOF 점검은 DNS, CDN, 오리진, DB, 인증 같은 인프라 컴포넌트 층위에서 진행되는데, 이번 5지점은 그보다 한 단계 위인 control plane이라는 운영 평면 자체에 집중합니다. 같은 컴포넌트가 잘 분산되어 있어도 control plane이 한 계정 위에 있으면 같은 시간에 같이 멈춘다는 점이 Railway 사건의 메시지였기 때문입니다.
Railway가 보고서에서 직접 발표한 향후 조치 두 가지가 그대로 점검 항목이 됩니다.
"removing this dependency, making this a true mesh" / "extending the high availability database shards across AWS and Metal" (Railway 공식 incident report, 2026-05-20)
의존성을 제거해 true mesh로 가고, 하이 어베일러빌리티 데이터베이스 샤드를 다른 클라우드와 베어 메탈까지 확장하겠다는 두 방향입니다. 이 두 방향을 한국 SaaS·핀테크·이커머스의 자체 점검 리스트로 정리하면 다섯 가지가 됩니다.
점검 지점 | 질문 | 잠재 위험 |
|---|---|---|
1. control plane 계정 단일 의존 | API·대시보드·운영 콘솔이 한 클라우드 계정 위에 모두 올라가 있는가 | 계정 자동 정지 시 운영 표면 동시 마비 |
2. 데이터베이스 위치 | 주 DB와 복제본이 같은 계정·같은 클라우드 안에만 존재하는가 | 계정 정지 시 데이터 접근 동시 차단 |
3. 인증·DNS | 로그인 인증과 도메인 DNS가 같은 클라우드의 매니지드 서비스에 묶여 있는가 | 인증 게이트 차단 시 페일오버 경로 없음 |
4. 운영 알람 채널 | 장애 알람·모니터링 대시보드가 영향 받는 클라우드 안에서만 작동하는가 | 장애 발생 자체를 인지 못 함 |
5. 복구 절차 문서화 | persistent disk → compute → network 순서 같은 복구 시나리오가 사전 검증돼 있는가 | 해제 후에도 단계 누락으로 추가 지연 |
이 다섯 가지는 Railway가 사후에 발표한 방향을 일반 SaaS 관점으로 정리한 항목입니다. 클라우드 자체를 떠나라는 뜻이 아니라, 한 계정에 모든 평면을 묶지 말라는 메시지입니다. 같은 시간에 같이 죽지 않는 두 번째 경로를 미리 두는 것이 핵심입니다.
Railway가 향한 방향, 멀티 클라우드를 넘어 true mesh로
이번 보고서에서 가장 중요한 단어는 true mesh입니다. Railway는 사고 시점에 이미 Metal·GCP·AWS 세 환경을 묶은 mesh ring을 운영하고 있었어요. 그런데도 network control plane API가 GCP 단일 호스팅이라는 hard dependency 때문에 mesh가 효력을 잃었죠. 그 dependency를 제거하고 mesh를 완성된 형태로 강화하는 것이 true mesh의 의미입니다.
true mesh는 자원과 control plane이 여러 공급자에 분산되어 있고 각 노드가 서로 독립적으로 동작하는 구조를 말합니다. 한 노드의 control plane이 멈춰도 나머지 노드는 영향을 받지 않고 자체 메타데이터로 트래픽을 계속 처리하죠. 단순히 백업을 다른 클라우드에 두는 것이 아니라, 운영 권한 자체가 한곳에 묶이지 않는 구조입니다.
Railway는 보고서에서 그 첫걸음으로 하이 어베일러빌리티 데이터베이스 샤드를 AWS와 Metal까지 확장한다고 명시했습니다. 즉 가장 중요한 데이터 계층부터 단일 공급자 의존을 해소하겠다는 의미입니다. 한국 SaaS도 이 순서를 참고할 수 있어요. 모든 계층을 한 번에 분산하기 어렵다면, 데이터부터 시작해 점진적으로 control plane을 분산해 가는 방향입니다.
물론 비용과 운영 복잡도가 따라옵니다. 다중 control plane은 동기화 비용, 데이터 일관성, 운영 자동화 도구의 중복 구축을 의미해요. 그래도 8시간 정지로 잃는 매출과 신뢰를 계산해 보면 어느 수준까지 분산할 가치가 있는지 결정이 쉬워집니다.
이것만 기억하세요
2026년 5월 19일 Railway가 Google Cloud의 자동화된 정책으로 8시간 정지된 사건은 단일 하이퍼스케일러 control plane 의존의 SPOF를 다시 한번 드러냈습니다. 영향은 컴퓨트뿐 아니라 대시보드, API, 네트워크 메타데이터까지 동시에 미쳤고, 정지 해제 후에도 persistent disk, compute, network 순으로 단계적 복구가 필요했어요. Railway가 발표한 향후 조치는 의존성 제거와 true mesh 구조, 그리고 데이터베이스 샤드를 AWS와 Metal까지 확장하는 두 가지입니다. 한국 SaaS·핀테크·이커머스 운영팀이 지금 점검할 것은 다섯 가지죠. control plane 단일 의존, 데이터베이스 위치, 인증·DNS 분리, 운영 알람 채널 독립, 복구 시나리오 사전 검증.
자주 묻는 질문 (FAQ)
Q. 이번 Railway 정지 사건의 핵심 사실은 무엇인가요?
Railway 공식 incident report 기준 2026년 5월 19일 22시 20분(UTC)에 Google Cloud가 Railway production 계정을 자동화된 절차에 따라 정지시켰어요. 계정 접근 자체는 22시 29분(UTC)에 9분 만에 복구됐지만, persistent disk와 compute, networking이 단계적으로 살아나며 영향이 완전히 종료된 monitoring 진입 시점은 다음 날 06시 14분(UTC) 무렵이었습니다. 한국 시각으로는 5월 20일 07시 20분부터 15시 14분까지 약 8시간 동안 영향을 받았죠. 영향 범위는 Railway 대시보드, API, 네트워크 인프라 일부, Google Cloud에 호스팅된 컴퓨트 인프라 전부였고, 사용자는 503 에러와 no healthy upstream, unconditional drop overload 메시지를 만나며 로그인 자체가 불가능했습니다.
Q. Google Cloud는 왜 Railway 계정을 정지시켰나요?
Railway 공식 보고서가 밝힌 원인은 한 줄입니다. Google Cloud가 Railway production 계정을 자동화된 절차의 일부로 잘못된 상태인 suspended로 변경했다는 것입니다. 즉 사람이 검토한 결정이 아니라 자동화 정책이 의도와 다르게 작동해 정지가 발생한 케이스죠. Google Cloud는 공식 사후 분석이나 대변인 코멘트를 공개하지 않았고, The Register가 보도 시점에 문의했지만 회신이 없었다고 명시했어요.
Q. 왜 control plane 정지가 8시간 가용성 사고로 번지나요?
Railway 보고서가 보여준 대로 control plane(계정·API·대시보드·네트워크 메타데이터)이 정지되면, 그 위에 묶여 있던 compute, persistent disk, networking이 함께 멈춥니다. 정지가 풀린 뒤에도 persistent disk, compute instance, networking 순서로 단계적으로 복구해야 해 정상 트래픽이 다시 흐르는 데 추가 시간이 들죠. 데이터 plane만 분산되어 있어도 control plane이 한 곳이면 단일 장애점이 됩니다.
Q. 한국 SaaS가 지금 점검할 우선순위는 무엇인가요?
Railway가 발표한 향후 조치 방향이 그대로 점검 항목이 됩니다. 첫째, 하이 어베일러빌리티 데이터베이스 샤드를 다른 클라우드(예: AWS, Metal)까지 확장해 데이터가 한 계정에 묶이지 않게 만드는 것입니다. 둘째, 의존성을 제거하고 true mesh 구조로 재설계해 control plane 자체를 분산하는 것이고요. 즉 멀티 리전이나 멀티 AZ로는 부족하고, 멀티 클라우드 계정·다중 control plane까지 가야 이번 같은 자동 정지에 영향을 덜 받습니다.
Q. 비슷한 사례가 과거에도 있었나요?
The Register는 2024년 Google Cloud가 호주 연금펀드 UniSuper의 인프라 전체를 삭제한 사례를 함께 언급했어요. 자동화·운영 실수로 단일 하이퍼스케일러 위에 올라간 고객 자원이 사라지거나 정지되는 패턴은 처음 본 사건이 아니라는 뜻이죠. Railway 사건과 UniSuper 사건의 공통점은 두 가지입니다. 하나는 사고가 사람의 결정이 아닌 자동화·운영 절차에서 시작됐다는 점, 다른 하나는 control plane 또는 자원 메타데이터가 한곳에 묶여 있어 단일 사건이 곧 전체 가용성으로 번졌다는 점이에요.




